
データstorageが大きくなるほど、必要なファイルを検索して見つけるのが難しくなります。ファイルの編成、分類、インデックス作成を適切に行わないと、ユーザーは必要なデータの取得に多大な生産時間を奪われてしまうことになります。
DataCore Swarmオブジェクトstorageプラットフォームは、最も効率的かつユーザーフレンドリーな方法でこの問題に対処し、問題を解決します。SwarmはElasticsearch検索エンジンとシームレスに統合されており、幅広いエクサバイト規模の検索および分析オプションを提供します。コマンドライン、SwarmのWebベースコンテンツPortal、Swarm APIからクエリと検索を実行できます。
Swarmを使用すると、ユーザーはオブジェクトとして保存されているファイルに多数のカスタムメタデータ属性を追加できるため、クエリ実行の柔軟性が向上します。エクサバイト単位でstorageを占有している数百万件のファイルを検索する場合でも、検索、クエリ、取得操作はほぼリアルタイムのスピードで実行されます。
Elasticsearchによって高速な検索操作が可能になる仕組み
Elasticsearchは、クラウド向けに構築された分散型のRESTfulオープンソース検索・分析エンジンであり、オブジェクトのメタデータのインデックスを非常に高速に作成できます。また、ユーザーは保存されているオブジェクトの属性とメタデータに対してアドホック検索を実行できるようになります。ElasticsearchとSwarmを統合することで、ユーザーが時間をかけずにファイルを検索できるリッチなメタデータベースの検索エクスペリエンスを提供します。
- ユーザー/アプリケーションによって発行された検索クエリがSwarmクラスタに到達します。
- Swarmクラスタは検索フィードを介して自動的にElasticsearchサービスに接続し、検索クエリとメタデータを送信します。
- Elasticsearchサーバーはメタデータのインデックスを作成し、検索クエリを処理します。
- 検索フィードによってElasticsearchからの返信がSwarmクラスタに返されます。ユーザー/アプリケーションはこれをSwarmコンテンツPortalで確認できます。
数分かかっていた手動でのファイル検索操作はわずか数秒に短縮され、手動での労力を節約でき、ユーザーの生産性を向上させます。

Swarmの検索機能のハイライト
Swarmの検索機能は、S3メタデータとの1:1のマップを作成し、以下を含む多くのメリットを提供します。
- ターゲット分析による実用的なインサイト
- 分類、キーワード、記述内容を使用したコンテンツの動的編成と、そのコンテンツを追跡する複数の方法
- storageシステム内で最適化された統合検索スタック
WebベースのPortal
一般的なWebベースのブラウザからすばやく定義、実行、結果の確認が可能です。
Swarm CLIからのクエリ
Swarmコマンドラインインターフェースからサポートされているクエリを実行して、コンテンツに直接アクセスできます。
堅牢なHTTP RESTfulインターフェース
サードパーティアプリケーションに統合するために、すべての検索機能はSwarm SCSP APIからも利用できます。
サードパーティアプリ統合
Amazon S3と直接接続して、Swarmからデータにアクセスできます。
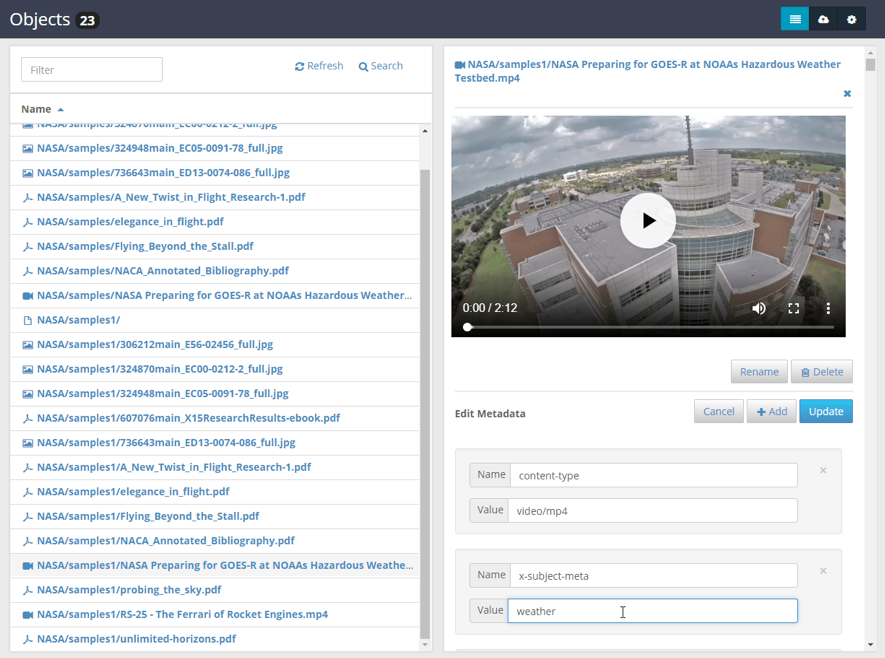
カスタムメタデータ
WebブラウザやAPIから、いつでも任意のファイルにカスタムメタデータを追加できます。
大量の結果セットのフィルタリングと編成
データをどのように編成、プレビュー、フィルタリングするかを正確に定義し、結果を制限したり、検索を絞り込んだりできます。
迅速に再利用するためにクエリを保存
すべての検索は動的に行われ、保存して再利用することで、後でクエリ作成を高速化できます。
結果をJSONまたはXMLにエクスポート
分析プラットフォームまたはプロセスへの統合のために、検索結果をJSONまたはXMLにエクスポートできます。
ELKスタックの活用
Elasticsearchは、LogstashおよびKibanaとシームレスに連携して分析と視覚化を行います。
ソフトウェアディファインドオブジェクトストレージであるSwarmを使ってみましょう
増大するデータをスケーラブルで安全なアクティブアーカイブに保存します。法外なクラウドコストはもう不要です。
DataCoreソリューションの恩恵を受けている数千人のITプロフェッショナルに加わりましょう。

「スケーラビリティはSwarmの最も優れた部分の1つです。素晴らしいのは、新しいノードをドロップすると、それがゼロから構築されるという点です。72テラバイトまたはペタバイトのノードを追加する場合も、ドロップするだけです。」
John Gillam – British Telecommunications
クラウドサービス担当CTO