
Lorsque des ensembles de données massifs, une infrastructure fragmentée et des workloads à haut débit se conjuguent, les systèmes de stockage classiques sont soumis à une énorme pression. Notamment, dans le cas d'environnements à forte densité de données, dans des domaines tels que l'IA, le HPC, les médias et la recherche, la gestion des flux de données entre différents niveaux, sites et clouds génère un goulet d'étranglement majeur.
Ngenea résout ce problème en mettant une automatisation intelligente entre vos applications et les couches de stockage. Il unifie votre stockage hétérogène sous un catalogue global, offre un tiering transparent et orchestre les actions du cycle de vie sans perturber les workflows ni compromettre les performances. Utilisé avec DataCore Pixstor, Ngenea améliore ses capacités grâce à une mobilité intelligente des données, en étendant le système de fichiers hautes performances dans une structure de données dynamique, pilotée par des stratégies.
- Étend le stockage existant grâce à l'orchestration, sans avoir à remplacer quoi que ce soit
- Prend en charge les cibles de stockage fichier, objet et cloud : NAS, S3, bande, etc.
- Crée un catalogue global avec un stubbing des fichiers pour un accès transparent aux données
- Automatise le placement, le rappel, la migration et l'archivage des données
- S'intègre aux planificateurs de tâches et aux workflows hybrides
- Permet la synchronisation et le rappel d'un site à l'autre
- Fournit une indexation complète des métadonnées et un contrôle piloté par API
- Se déploie sur site, dans le cloud ou dans des environnements hybrides
Cas d’usage
Environnements HPC hybrides nécessitant un déplacement transparent des données entre les niveaux de calcul, de stockage et d'archivage.
Pipelines d'entraînement de modèles IA nécessitant une ingestion rapide, une mise en préproduction et un point de contrôle d'archivage.
Workflows des médias nécessitant un déplacement transparent entre les niveaux production, rendu, archivage et cloud.
Collaboration mondiale avec accès à distance aux données via une vue unifiée et un rappel intelligent
Cloud bursting et DR avec caching intelligent, pré-extraction et déplacement de données économique
Équipes multi-sites avec accès distribué aux données et gouvernance du cycle de vie
Fonctionnalités
Ngenea fait abstraction de l'ensemble du stockage pour en faire une représentation logique unique, qui élimine les silos, tout en permettant un tiering et un rappel automatiques en fonction de stratégies entre les niveaux et les emplacements.
- Catalogue basé sur des stubs avec rappel transparent sur consultation
- Déplacement de données basé sur des stratégies en fonction de l'ancienneté, du chemin d'accès, des balises, de l'accès et de l'utilisation
- Tiering entre les stockages NVMe, SSD, HDD, objet, bande, cloud, NAS
- Hydratation des fichiers à la demande ou pré-extraction via les hooks du planificateur de tâches
- Conserve les métadonnées, les autorisations et les chemins d'accès d'origine
- Fonctionne avec le stockage existant grâce à un stubbing inversé
- Aucune reconfiguration des applications ou des utilisateurs n'est nécessaire
Automatisez le déplacement des données entre les couches de performances et de capacité en fonction de l'utilisation réelle, des stratégies et des workflows, sans affecter l'accès ni rompre les chemins d'accès.
- Tiering basé sur des règles par ancienneté, taille, propriétaire, emplacement, balises ou activité
- Déplacement transparent des données entre les types de stockage NVMe, SSD, disque dur, objet, bande et cloud.
- Conservation des chemins d'accès, des autorisations et des métadonnées des fichiers
- Rappel (hydratation) des fichiers à la demande ou basé sur des stratégies, selon les besoins
- Intégration aux gestionnaires de workflow et aux planificateurs de tâches
- Stubbing inversé permettant l'accès aux données existantes, ce qui réduit la migration
- Alignement du tiering sur les objectifs de performances, de coût et de conservation
- Contrôle granulaire pour les scénarios de mise en préproduction, d'archivage ou de bursting
- Outils d'analyse de la capacité fournissant des informations sur les schémas d'utilisation afin de planifier les décisions de tiering plus efficacement
Ngenea suit et indexe les métadonnées sur l'ensemble du stockage connecté, offrant une visibilité complète et des possibilités d'action quel que soit l'emplacement physique.
- Index central des noms de fichiers, des chemins d'accès, des balises, des horodatages
- Prise en charge des métadonnées de contenu et de métadonnées personnalisées pour l'accessibilité des données
- Accès à l'interface graphique et à l'API pour rechercher, filtrer et extraire des résultats
- Prévisualisation des proxys disponibles pour les données archivées ou froides
- Intégré à Pixstor Search et aux pipelines externes
- Exportation des résultats de recherche vers des workflows d'action
Ngenea accélère les déplacements et la réplication entre les environnements, sans la complexité liée aux transferts manuels ou à une infrastructure dédiée.
- Synchronisation efficace avec un surcoût minime
- Options de synchronisation bidirectionnelle et déshydratée (stub uniquement)
- Prend en charge les types de synchronisation POSIX↔POSIX, POSIX↔S3, S3↔S3
- Transferts tenant compte de la bande passante et contrôle par chemin d'accès
- Rappel inversé facilitant la DR : n'extrait que ce qui est nécessaire
- Peut migrer facilement des milliards de fichiers
Ngenea s'intègre à vos workflows informatiques pour automatiser les actions de préparation, de mise en préproduction et de post-traitement des données.
- API REST et Python pour les déclencheurs pré/post-tâche
- Prend en charge les toolchains Slurm, Portable Batch System (PBS) et CI/CD
- Déclencheurs basés sur des fichiers et des événements pour une automatisation complète
- Mettez les données en préproduction sur un stockage scratch avant une tâche et archivez-les après.
- Modèle de chariot d'action pour le déplacement ou le nettoyage programmé
Ngenea garantit un accès sécurisé et soumis à des règles sur tous les niveaux et les sites, sans affecter la productivité des utilisateurs.
- Contrôle d'accès basé sur les rôles (RBAC) à tous les niveaux
- Prend en charge l'authentification AD, LDAP, OAuth2
- Enregistrement d'audit pour les événements de rappel, de déplacement et d'accès
- Mise en œuvre de la conservation via des stratégies de snapshot et de tiering
- Chiffrement lors du transfert (TLS/SSH) et au repos en option
- Règles spécifiques au site, limites de rappel et disponibilité des DR
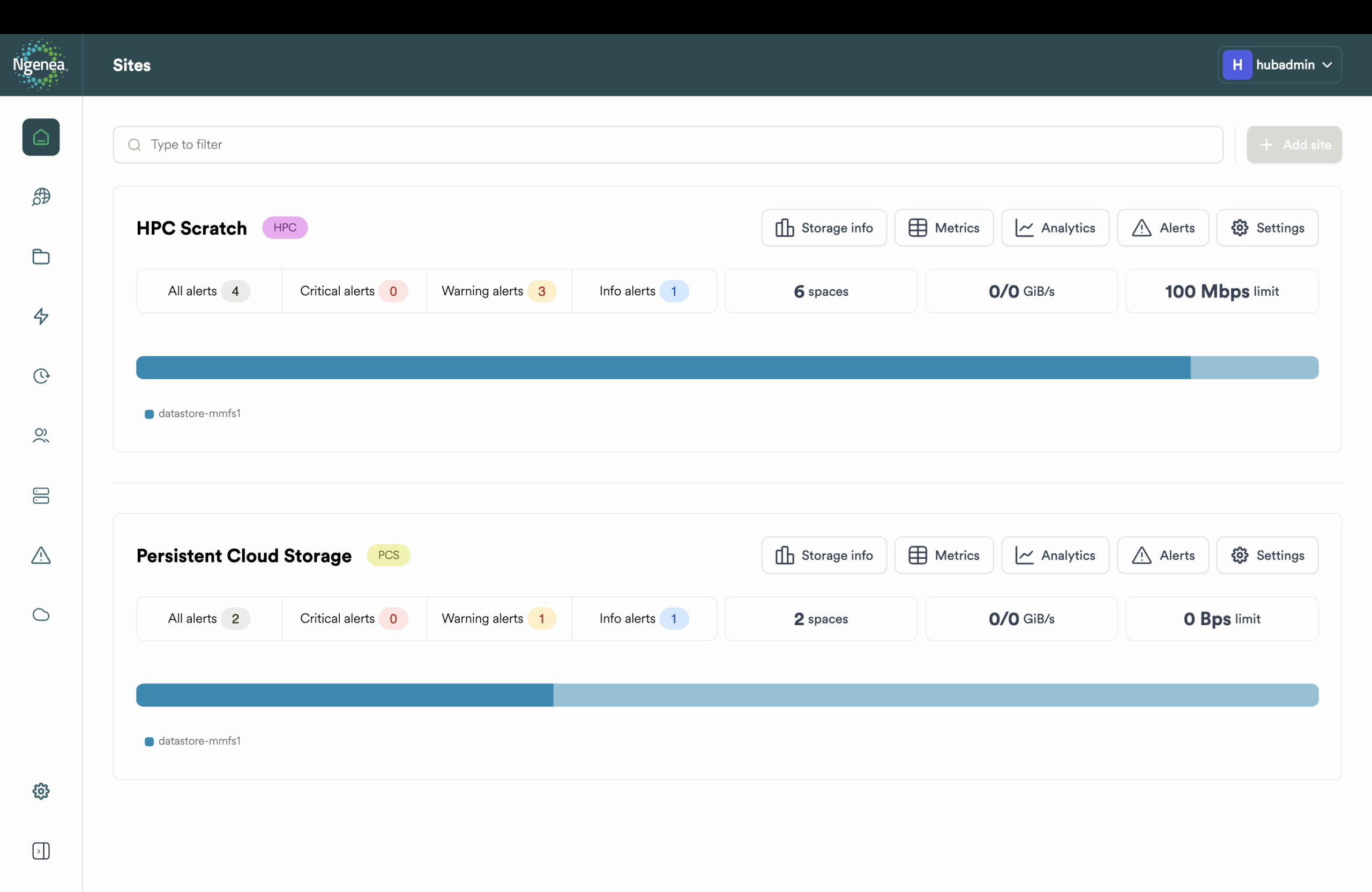
Des tableaux de bord au contrôle programmatique, Ngenea offre une visibilité totale sur l'emplacement de vos données, leur utilisation et leur coût.
- Tableau de bord central pour l'état des stratégies, la file d'attente des rappels et l'utilisation.
- Enregistrement des événements et du système via Logstash, Elasticsearch
- Alertes par e-mail pour les seuils clés et les événements du système
- Hooks d'automatisation pour le cycle de vie et les actions stratégiques
- API REST pour l'intégration et l'orchestration
- Déclencheurs personnalisés pour l'ingestion, la synchronisation, la migration et la reprise après sinistre
Ngenea étend l'orchestration à n'importe quelle destination, qu'il s'agisse d'un Cloud hyperscale, d'une archive profonde ou d'un site d'ingestion Edge.
- S'intègre à AWS, Azure, GCP et aux stockages objet privés
- S'intègre à DataCore Swarm pour l'archivage S3 sur site
- Prend en charge le stockage sur bande via BlackPearl et le stockage NAS via NFS/S3
- Rappel et indexation transparents basés sur des stubs sur toutes les cibles
- Caching et archivage cloud contrôlés par des stratégies
- Tiering basé sur des stratégies en fonction du coût, de l'utilisation ou des workflows
- Prend en charge les environnements hybrides et multi-cloud

Collaboration mondiale
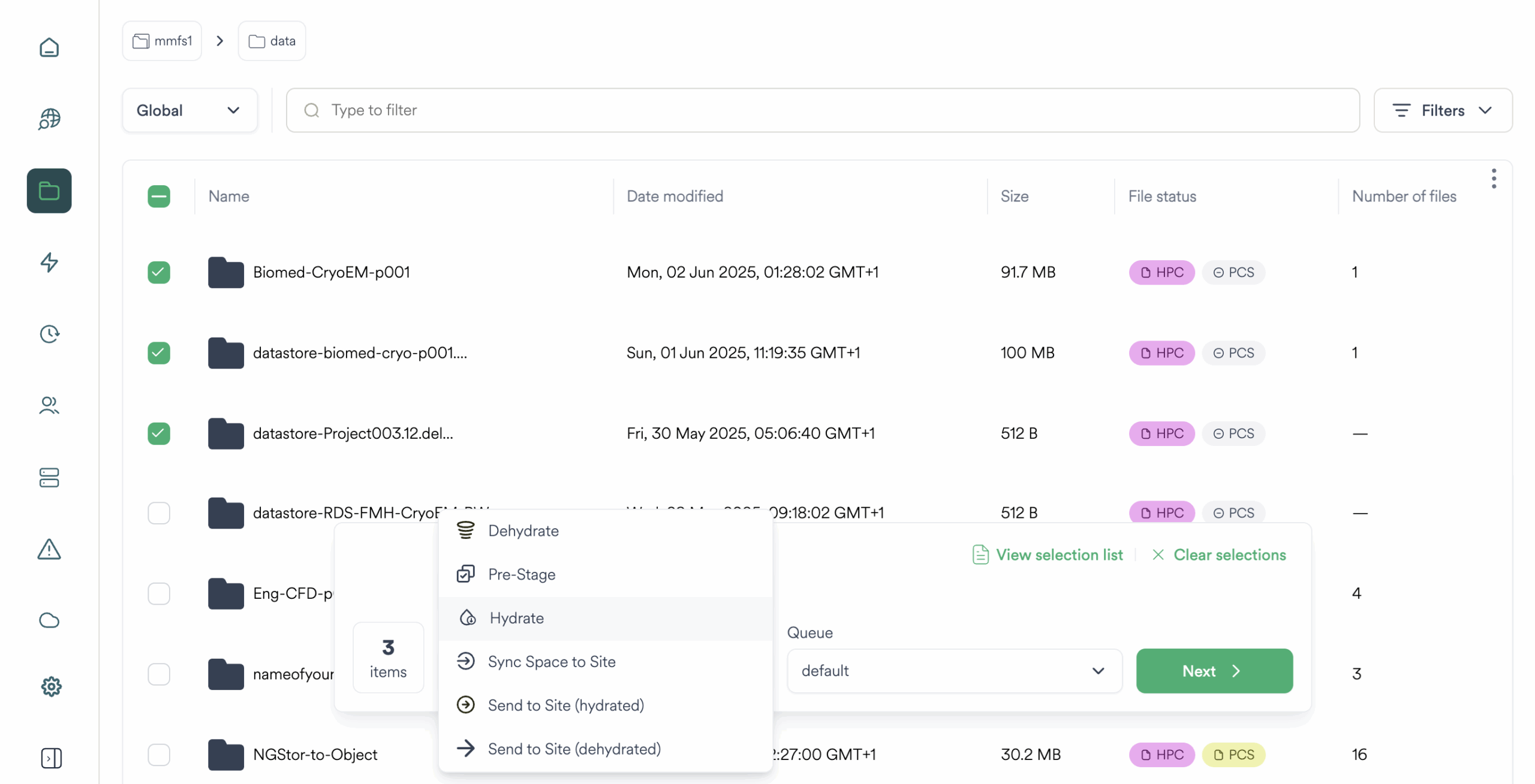
Gestion des données basée sur des stratégies
Catalogue unifié entre les sites et les emplacements
Avantages
Automatisez les tâches complexes

- Planifiez et déclenchez des flux de données à l'aide de règles et de stratégies : sans aucune intervention manuelle.
- Orchestrez les données de l'acquisition à l'archivage, sans interruption pour l'utilisateur
- Réduisez les coûts d'exploitation sur l'ensemble des sites
Optimisez le placement des données et les coûts

- Ayez l'assurance que les données chaudes restent sur le stockage rapide et archivez automatiquement les données froides.
- Appliquez des stratégies de rentabilité pour éviter les dépenses imprévues liées au Cloud
- Exploitez les systèmes de stockage existants et choisissez librement votre matériel supplémentaire : sans aucune dépendance vis-à-vis d'un fournisseur
Favorisez une collaboration mondiale

- Les équipes distantes travaillent à l'unisson grâce à un catalogue unifié
- L'accès par stub garantit que les fichiers sont toujours accessibles
- Les données sont rappelées à la demande ou mises en préproduction selon les besoins.
- L'accès basé sur les rôles garantit que les utilisateurs ne voient que ce dont ils ont besoin.
Accélérez les workloads

- Les données se trouvent là où elles doivent être avant même le début des tâches de calcul
- Mise en préproduction, mise en cache et hydratation sans délai
- Simplifiez les workflows entre les environnements core, edge et cloud
Protégez et récupérez avec précision

- DR basé sur des stubs avec un faible encombrement
- Synchronisation et rappel basés sur des stratégies entre les niveaux de stockage et les sites
- Récupération rapide sans réplication complète de l'ensemble de données
Pérennisez votre stratégie de stockage

- Intégrez facilement de nouveaux matériels, stockages ou sites
- Répartissez vos données sur le cloud ou des bandes sans interrompre les workflows
- Faites évoluer les opérations et les emplacements sans avoir à repenser l'accès
Architecture

Architecture de référence de DataCore Ngenea et Pixstor pour les environnements HPC/IA
Déploiement
Ngenea et Pixstor peuvent être déployés sur site, sur le cloud ou sous forme de solution hybride. Vous bénéficiez ainsi de la flexibilité nécessaire pour prendre en charge n'importe quelle stratégie de workflows ou d'infrastructure.
Licence
La licence de Ngenea est octroyée par serveur. Une seule licence serveur permet de déplacer les données sur un nombre illimité de cibles de stockage (y compris scratch, home, archive et cloud), sans limite de capacité ni frais liés aux performances. Cela permet d'éliminer les coûts cachés, d'éviter les frais de capacité lors de l'extension du catalogue ainsi que de mettre au rebut ou de réaffecter le matériel sans générer de coûts de licence supplémentaires. Ngenea est disponible exclusivement auprès de Pixstor.