
When massive datasets, fragmented infrastructure, and high-throughput workloads collide, they place enormous strain on traditional storage systems. This is especially true for data-heavy environments like AI, HPC, media, and research, where managing the flow of data across tiers, sites, and clouds becomes a major bottleneck.
Ngenea solves this by placing intelligent automation between your applications and storage layers. It unifies your heterogeneous storage under a global namespace, enables transparent tiering, and orchestrates lifecycle actions without disrupting workflows or compromising performance. When used with DataCore Pixstor, Ngenea enhances its capabilities with smart data mobility, extending the high-performance file system into a dynamic, policy-driven data fabric.
- Extends existing storage with orchestration; no rip-and-replace
- Supports file, object, and cloud targets: NAS, S3, tape, and more
- Creates a global namespace with file stubbing for seamless data access
- Automates data placement, recall, migration, and archive
- Integrates with job schedulers and hybrid workflows
- Enables site-to-site sync and recall across locations
- Provides full metadata indexing and API-driven control
- Deploys on-premises, in the cloud, or hybrid environments
Use Cases
Hybrid HPC environments that require seamless data movement between compute, scratch, and archive tiers
AI model training pipelines requiring fast ingest, pre-staging, and checkpoint archival
Media workflows needing seamless movement between production, render, archive, and cloud tiers
Global collaboration with remote access to data through a unified view and smart recall
Cloud bursting and DR with intelligent caching, prefetch, and cost-efficient data movement
Multi-site teams with distributed data access and lifecycle governance
Features
Ngenea abstracts all storage into a single logical view, eliminating silos while enabling automated, policy-driven tiering and recall across tiers and locations.
- Stub-based namespace with seamless recall on access
- Policy-based data movement based on age, path, tags, access, usage
- Tiering between NVMe, SSD, HDD, object, tape, cloud, NAS
- File hydration on-demand or prefetch via job scheduler hooks
- Maintains original metadata, permissions, and paths
- Works with legacy storage via reverse stubbing
- No reconfiguration of apps or users required
Automate the movement of data between performance and capacity layers based on real usage, policies, and workflows without impacting access or breaking paths.
- Rule-based tiering by age, size, owner, location, tags, or activity
- Transparent data movement between NVMe, SSD, HDD, object, tape, and cloud
- Preserves file paths, permissions, and metadata
- On-demand or policy-driven recall (hydration) of files as needed
- Integrates with workflow managers and job schedulers
- Reverse stubbing enables legacy data access, reducing migration
- Align tiering to performance, cost, and retention goals
- Granular control for staging, archiving, or bursting scenarios
- Capacity analysis tools provide insights into usage patterns to plan tiering decisions more effectively
Ngenea tracks and indexes metadata across all connected storage, providing complete visibility and actionability regardless of physical location.
- Central index of file names, paths, tags, timestamps
- Supports content metadata and custom metadata for data discoverability
- GUI and API access to search, filter, and retrieve results
- Preview proxies available for archived or cold data
- Integrated with Pixstor Search and external pipelines
- Export search results to action workflows
Ngenea accelerates movement and replication across environments without the complexity of manual transfers or dedicated infrastructure.
- Efficient sync with minimal overhead
- Bi-directional and dehydrated sync (stub only) options
- Supports POSIX↔POSIX, POSIX↔S3, S3↔S3 sync types
- Bandwidth-aware transfers and per-path control
- DR-friendly reverse recall: only fetch what’s needed
- Can migrate billions of files with ease
Ngenea integrates with your compute workflows to automate data prep, staging, and post-processing actions.
- REST and Python APIs for pre/post job triggers
- Supports Slurm, Portable Batch System (PBS), and CI/CD toolchains
- File-based and event-based triggers for full automation
- Stage data to scratch before a job; archive it after
- Action cart model for scheduled movement or cleanup
Ngenea ensures secure, policy-bound access across all tiers and locations, without impacting user productivity.
- Role-based access control (RBAC) at all layers
- Supports AD, LDAP, OAuth2 authentication
- Audit logging for recall, movement, and access events
- Retention enforcement via snapshot and tiering policies
- Encryption in transit (TLS/SSH) and optionally at rest
- Site-specific rules, recall limits, and DR availability
From dashboards to programmatic control, Ngenea provides full visibility into where your data is, how it is used, and what it costs.
- Central dashboard for policy status, recall queue, and usage
- Event and system logging via Logstash, Elasticsearch
- Email alerts for key thresholds and system events
- Automation hooks for lifecycle and policy actions
- REST APIs for integration and orchestration
- Custom triggers for ingest, sync, migration, and DR
Ngenea extends orchestration to any destination—be it hyperscale cloud, deep archive, or edge ingest site.
- Integrates with AWS, Azure, GCP, and private object stores
- Integrates with DataCore Swarm for on-premises S3 archive
- Supports tape via BlackPearl and NAS via NFS/S3
- Stub-based transparent recall and indexing across all targets
- Policy-controlled cloud caching and archival
- Policy-based tiering based on cost, usage, or workflows
- Supports hybrid and multi-cloud environments

Global Collaboration
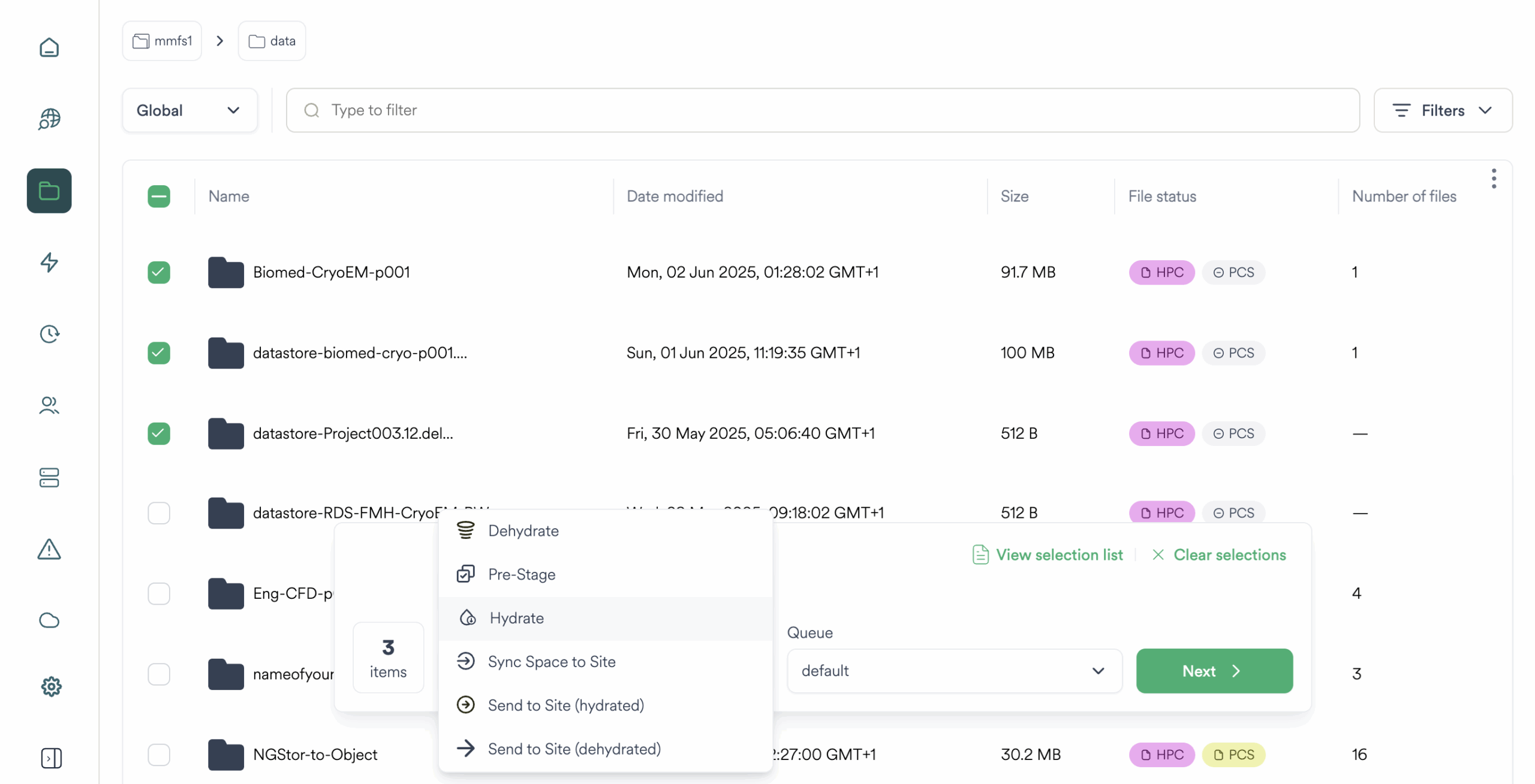
Policy-Based Data Management
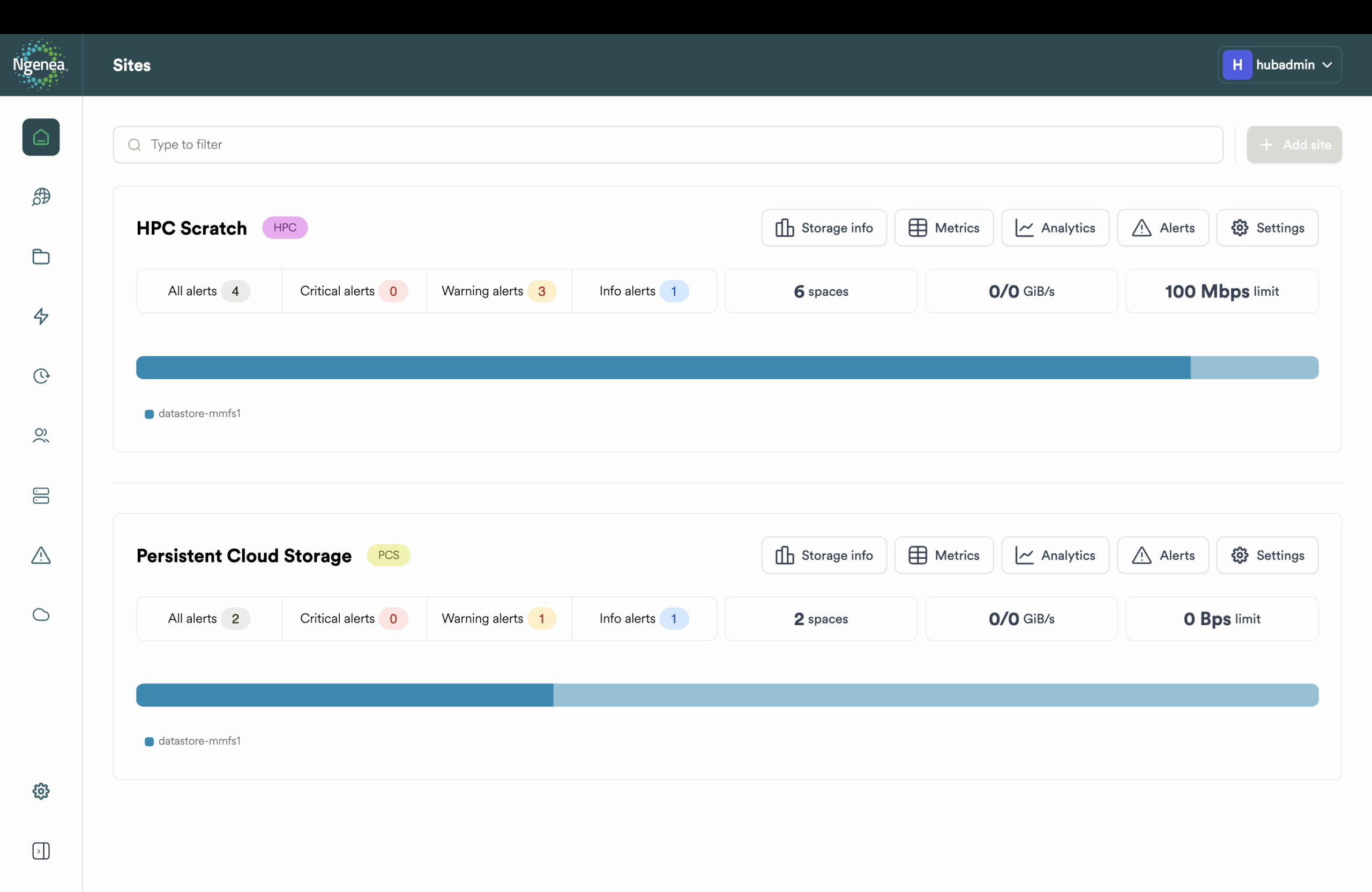
Unified Namespace Across Sites & Locations
Benefits
Automate The Complex Stuff

- Schedule and trigger data workflows with rules and policies: no manual intervention
- Orchestrate data from ingest to archive without user disruption
- Reduce operational overhead across locations
Optimize Data Placement & Cost

- Ensure hot data stays on fast storage; archive cold data automatically
- Enforce cost-aware policies to avoid unexpected cloud spend
- Leverage existing storage systems and expand with free choice of hardware: no vendor lock-in required
Enable Global Collaboration

- Remote teams work as one through unified namespace
- Stub access ensures files are always discoverable
- Data is recalled on-demand or pre-staged as needed
- Role-based access ensures users see only what they need
Accelerate Workloads

- Data is where it needs to be even before compute jobs start
- Pre-stage, cache, and hydrate without delays
- Simplify workflows from core to edge to cloud
Protect & Recover with Precision

- Stub-based DR with low footprint
- Policy-driven sync and recall across storage tiers and sites
- Fast recovery without full dataset replication
Future-Proof Your Storage Strategy

- Easily integrate new hardware, storage, or sites
- Tier to cloud or tape without disrupting workflows
- Scale operations and locations without reinventing access
Architecture

DataCore Nexus (Pixstor & Ngenea) Reference Architecture for HPC/AI Environments
Deployment
Pixstor and Ngenea are available as a fully integrated turnkey appliance called Nexus. Each Nexus appliance includes the required Pixstor components, such as storage nodes, gateway nodes, and management nodes, along with Ngenea orchestration services, all delivered in a simplified appliance model. This compact, converged architecture provides a scalable and flexible foundation for high-performance workflows and data management.
Licensing
Licensing is based on two key factors: the number of Nexus appliances deployed and the total usable Pixstor capacity in the solution. Ngenea functionality can be added to the appliance as required. Data moved by Ngenea between external storage tiers (such as object storage, cloud, tape, etc.) is not counted toward licensing and does not incur additional cost. This model provides predictable scaling without performance-tier surcharges or hidden infrastructure licensing costs, while allowing flexible expansion of storage, orchestration, and data management capabilities as requirements grow.