
Lorsqu’un système de stockage externe traditionnel n’est plus suffisant, c’est généralement parce que l’infrastructure a évolué plus vite que le data plane. Pendant des années, le secteur a fonctionné sur l’hypothèse que le stockage était une entité statique — une « boîte noire » située en dehors du cluster de calcul. Mais à mesure que Red Hat OpenShift devient la pierre angulaire du data center moderne, cette séparation n’est plus une simple nuance architecturale : elle devient un goulot d’étranglement en matière de performance.
Depuis le début de 2024, l’adoption de Red Hat OpenShift a accéléré à des niveaux sans précédent. Selon des données récentes de Red Hat, l’adoption d’OpenShift Virtualization par les clients a augmenté de 178 % depuis début 2024, avec une croissance significative des déploiements en production, alors que les organisations recherchent une alternative stable et évolutive aux hyperviseurs legacy. Cette évolution est portée par le besoin d’un socle unifié capable de gérer à la fois des microservices conteneurisés et des machines virtuelles traditionnelles. Cependant, à mesure que ces environnements se dimensionnent, on découvre rapidement que si OpenShift peut orchestrer des milliers de conteneurs en quelques secondes, le stockage sous-jacent peine souvent à suivre.
Défi du stockage OpenShift : la friction “stateful” dans un monde stateless
Le secteur présente souvent le Container Storage Interface (CSI) comme la solution universelle au stockage Kubernetes. En pratique, le CSI n’est qu’un traducteur : il permet à OpenShift de « communiquer » avec un array externe, mais il ne résout pas le décalage fondamental entre orchestration distribuée et stockage centralisé.
Le problème n’est pas seulement la connectivité, mais la latence et le comportement déterministe.
Lorsque l’on exécute des workloads stateful à haute performance — comme PostgreSQL, Kafka ou des pipelines d’entraînement IA — sur OpenShift, on rencontre l’effet « I/O Blender ». Les SAN traditionnels sont conçus pour un monde prévisible et lent de serveurs physiques. Dans un environnement OpenShift dynamique, les pods sont éphémères : ils se déplacent, se mettent à l’échelle, échouent et redémarrent sur d’autres nœuds.
Si la couche de stockage OpenShift n’est pas native Kubernetes, trois problèmes critiques apparaissent :
- Latence de montage : attendre qu’un SAN réassocie une LUN à un nouveau nœud lors d’un déplacement de pod peut prendre plusieurs minutes. Dans une architecture microservices, cela est une éternité.
- Incohérence des performances : les arrays traditionnels n’ont souvent pas la granularité nécessaire pour prioriser certains Persistent Volume Claims (PVC), entraînant des effets de “noisy neighbor” qui dégradent les performances.
- Complexité des opérations Day 2 : gérer le stockage via une console séparée, en dehors des workflows oc CLI ou GitOps d’OpenShift, casse la chaîne d’automatisation.
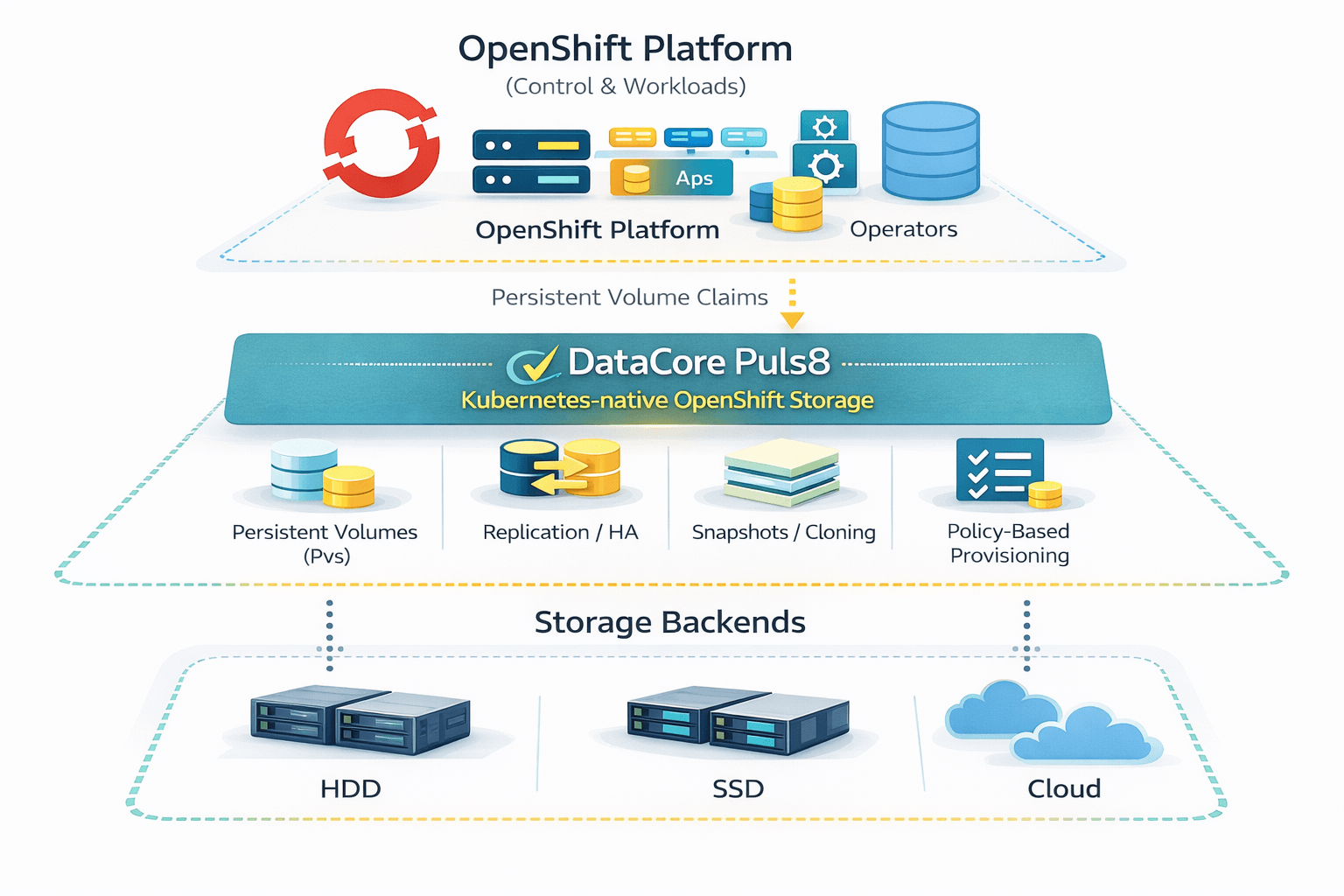
La solution : DataCore Puls8 comme fabric de stockage OpenShift
DataCore Puls8 est conçu pour éliminer la friction entre l’orchestrateur et le stockage. Plutôt que de fonctionner comme une extension externe, Puls8 agit comme un fabric de stockagedistribué intégré au cluster OpenShift. Il traite le stockage comme un composant natif de la stack Kubernetes.
Puls8 résout cet écart en déplaçant le data plane dans l’espace kernel des nœuds worker, garantissant un comportement de performance déterministe. Lorsqu’un volume est provisionné via une StorageClass, Puls8 ne se contente pas de réserver de l’espace sur un array : il orchestre un chemin de données haute performance utilisant NVMe-over-Fabrics (NVMe-oF), maintenant une latence inférieure à la milliseconde quelle que soit la taille du cluster.
Grâce à la réplication synchrone, Puls8 garantit la disponibilité des données sur plusieurs zones de disponibilité ou nœuds. Il ne s’agit pas seulement de sauvegarde, mais de continuité opérationnelle : si un nœud tombe, les données existent déjà ailleurs, permettant au scheduler OpenShift de redémarrer immédiatement le pod sans attente de remappage storage complexe.
Cas pratique : résilience réelle dans un cluster OpenShift
Prenons un scénario courant : un cluster MongoDB critique exécuté sur OpenShift sur trois nœuds.
Dans une architecture traditionnelle, si le nœud 1 tombe, le scheduler OpenShift déplace le pod MongoDB vers le nœud 2. Le driver CSI doit alors demander au SAN externe de démonter le volume du nœud 1 et de le remonter sur le nœud 2. Si la commande de démontage se bloque — ce qui arrive fréquemment dans les architectures legacy — le volume reste verrouillé et la base de données reste hors ligne.
Avec DataCore Puls8, le processus est automatisé et déterministe :
- Provisioning : une StorageClass Puls8 est définie avec un facteur de réplication de trois. Les données sont automatiquement distribuées sur les nœuds worker.
- Panne : le nœud 1 tombe de manière inattendue.
- Récupération : OpenShift détecte la panne et redéploie le pod sur le nœud 2. Comme Puls8 maintient déjà une réplication synchrone bit-à-bit des données sur ce nœud, le volume est immédiatement disponible.
- Résultat métier : aucune intervention manuelle, aucun verrou SAN obsolète, et aucune interruption prolongée. L’application reprend en quelques secondes.
Cette approche transforme le stockage d’un composant réactif en un service automatisé. On ne gère plus des LUN ou du masking, mais des politiques via les mêmes manifests YAML que les applications.
Conclusion : concevoir pour la certitude
Le passage à OpenShift est une décision stratégique visant à adopter une infrastructure moderne et automatisée. Cependant, cette stratégie n’est solide que si son maillon le plus faible l’est aussi. S’appuyer sur des architectures de stockage legacy pour alimenter une plateforme conteneurisée de nouvelle génération introduit des risques et une complexité opérationnelle inutiles.
![]()
DataCore Puls8 crée lepont entre l’agilité de Kubernetes et la fiabilité exigée par l’entreprise. Il ne s’agit pas simplement de fournir de la « capacité » aux conteneurs, mais de proposer un data plane résilient et performant qui scale linéairement avec les ambitions de l’organisation. L’enjeu est de garantir que les données sont protégées et que les performances sont assurées — et non de l’espérer.

