Les données ne cessent de croître au sein d’une organisation. Et parallèlement, les besoins de stockage augmentent avec elles. Les équipes informatiques chargées de la gestion du stockage des données doivent constamment résoudre des problèmes de manque de capacité imminent et investir toujours plus en matériel pour répondre à la demande de l’entreprise. La déduplication et la compression des données sont des techniques couramment utilisées pour rendre la gestion de la capacité de stockage plus efficace.
Pour optimiser la capacité à l’aide de la déduplication et de la compression, les équipes informatiques disposent de deux options de mise en œuvre : soit en ligne, soit en post-traitement. Ce blog examine et compare les deux types d’implémentation, en les illustrant par des cas d’utilisation afin de déterminer à quel moment recourir à la solution de déduplication de données.
Présentation rapide de la déduplication et de la compression des données
![]() La DÉDUPLICATION évite l’écriture de blocs de données en double et les remplace par un pointeur vers leur première version dans le même ensemble de données. Chaque bloc de données entrant est analysé et reçoit une valeur de hachage unique. Si un nouveau bloc écrit sur le disque a la même valeur de hachage qu’un bloc existant, il est remplacé par un identifiant qui pointe vers le bloc de données existant. Cela économise l’espace disque que les blocs de données redondants auraient autrement utilisé dans le pool de stockage. Les avantages de la déduplication sont plus importants lorsqu’il existe plusieurs blocs de mêmes données, par exemple, la redondance qui se trouve dans des snapshots ou des images VDI. En règle générale, le stockage principal aura moins de données en double, les archives périodiques en auront comparativement davantage et les sauvegardes répétées en auront considérablement plus.
La DÉDUPLICATION évite l’écriture de blocs de données en double et les remplace par un pointeur vers leur première version dans le même ensemble de données. Chaque bloc de données entrant est analysé et reçoit une valeur de hachage unique. Si un nouveau bloc écrit sur le disque a la même valeur de hachage qu’un bloc existant, il est remplacé par un identifiant qui pointe vers le bloc de données existant. Cela économise l’espace disque que les blocs de données redondants auraient autrement utilisé dans le pool de stockage. Les avantages de la déduplication sont plus importants lorsqu’il existe plusieurs blocs de mêmes données, par exemple, la redondance qui se trouve dans des snapshots ou des images VDI. En règle générale, le stockage principal aura moins de données en double, les archives périodiques en auront comparativement davantage et les sauvegardes répétées en auront considérablement plus.
![]() La COMPRESSION est un processus algorithmique qui réduit la taille des données en trouvant d’abord les séquences de données identiques qui apparaissent dans une ligne, puis en enregistrant uniquement la première et en remplaçant les suivantes par des informations sur le nombre de leur apparition dans la ligne.
La COMPRESSION est un processus algorithmique qui réduit la taille des données en trouvant d’abord les séquences de données identiques qui apparaissent dans une ligne, puis en enregistrant uniquement la première et en remplaçant les suivantes par des informations sur le nombre de leur apparition dans la ligne.
La réduction de la taille des données à un niveau binaire permet de consommer moins d’espace disque et, par conséquent, de stocker davantage de données dans la capacité disponible. La compression dépend de la nature de l’ensemble de données lui-même : s’il est dans un format compressible et dans quelle mesure il peut être compressé. Normalement, les chaînes de caractères en double (par exemple, les espaces supplémentaires) sont éliminées à l’aide d’un algorithme de compactage, puis les données compressées sont stockées dans des blocs de compression dans le périphérique de stockage. Ce type de compression est sans perte (n’entraîne aucune perte de données).
Sachant cela, examinons maintenant les deux méthodes que nous voulions comparer dans ce blog : déduplication et compression en ligne ou post-traitement.
Déduplication et compression en ligne
 Le traitement en ligne est une méthode largement utilisée pour mettre en place une forme de déduplication et de compression dans laquelle la réduction des données a lieu avant que les données entrantes ne soient écrites sur le support de stockage. L’outil de déduplication et de compression est généralement une solution de software-defined storage (SDS) ou un contrôleur de stockage qui l’emplacement des données et leurs modalités de placement. Toutes les données qui traversent l’outil sont analysées, dédupliquées et compressées en temps réel. Le traitement en ligne réduit généralement la capacité du disque brut dont le système a besoin puisque l’ensemble de données non dédupliqué et non compressé, c’est-à-dire ayant sa taille d’origine, n’est jamais écrit sur le disque. Les opérations d’écriture exécutées sont donc, elles aussi, proportionnellement moins intenses, ce qui limite l’usure des disques.
Le traitement en ligne est une méthode largement utilisée pour mettre en place une forme de déduplication et de compression dans laquelle la réduction des données a lieu avant que les données entrantes ne soient écrites sur le support de stockage. L’outil de déduplication et de compression est généralement une solution de software-defined storage (SDS) ou un contrôleur de stockage qui l’emplacement des données et leurs modalités de placement. Toutes les données qui traversent l’outil sont analysées, dédupliquées et compressées en temps réel. Le traitement en ligne réduit généralement la capacité du disque brut dont le système a besoin puisque l’ensemble de données non dédupliqué et non compressé, c’est-à-dire ayant sa taille d’origine, n’est jamais écrit sur le disque. Les opérations d’écriture exécutées sont donc, elles aussi, proportionnellement moins intenses, ce qui limite l’usure des disques.
Remarque : lorsqu’il s’agit de sauvegarde, la déduplication en ligne est également appelée déduplication à la source.
Déduplication et compression post-traitement
Dans la méthode par post-traitement, les données sont d’abord écrites sur le support de stockage, puis analysées pour y rechercher des possibilités de duplication et de compression. Puisque les opérations de déduplication et de compression ne sont exécutées que lorsque les données ont été stockées une fois sur le périphérique de stockage, la capacité initiale requise est identique à la taille des données brutes (avant réduction). Une fois optimisées en fonction de la capacité, les données sont sauvegardées sur le support de stockage, où elles nécessitent potentiellement moins d’espace qu’avant leur réduction.
Remarque : lorsqu’il s’agit de sauvegarde, la déduplication post-traitement est également appelée déduplication à la cible.

Quand utiliser telle ou telle méthode d’optimisation de la capacité
- En cas de contraintes d’attribution de capacité du disque sur le périphérique cible, il est préférable d’utiliser le traitement en ligne. En effet, l’espace de stockage nécessaire se limite alors à celui des données dédupliquées et compressées (inférieur à celui des données brutes complètes).
- Si les performances doivent être garanties en permanence et s’il existe une incertitude quant au potentiel d’optimisation de la capacité et à son impact sur les performances, le post-traitement sera plus indiqué. Puisque l’optimisation de la capacité intervient après le stockage des données, l’impact sur les performances reste faible au moment où les données sont écrites.
- Lorsque les données à écrire paraissent visiblement propices à l’optimisation de la capacité (par exemple, s’il y a un fort volume de données redondantes à dédupliquer ou s’il s’agit de types de données spécifiques acceptant des taux de compression plus élevés), le traitement en ligne utilisera l’espace plus efficacement et offrira probablement des performances de stockage encore meilleures car les opérations d’écriture seront minimisées et l’usure du disque sera donc réduite. Il faut toutefois pour cela que l’administrateur du stockage ou de l’outil informatique connaisse la nature des données écrites et puisse estimer au préalable l’efficacité de la réduction des données.
- Si vous souhaitez maîtriser le moment où l’optimisation de la capacité doit avoir lieu, le post-traitement sera préférable car son exécution peut être programmée à un moment de faible activité des applications. Cela pourra aussi aider à éviter les risques d’impact négatif sur les performances, en particulier en cas de pic de charge et d’activité des applications.
Facteurs influant sur les types de compression et de déduplication
Au moment de définir les objectifs d’économie de la capacité et de choisir entre la méthode de réduction des données en ligne ou la méthode de réduction post-traitement, il faut tenir compte de facteurs déterministes que nous allons traiter ci-dessous. Ceux-ci ont en effet un impact sur les taux d’efficacité de la déduplication et de la compression et contribuent donc à influencer positivement ou négativement les performances du stockage :
- Type de données : le type de données est essentiel pour savoir dans quelle mesure celles-ci peuvent être dédupliquées ou compressées. Dans le cas des bases de données, un certain niveau de suppression des redondances existe déjà au niveau de l’application. Leur déduplication et leur compression risquent donc de ne pas générer d’importantes économies. Il est possible que des snapshots d’images du système d’exploitation (comme dans un environnement VDI) fournissent de meilleurs taux d’optimisation de la capacité.
- Taux de modification des données : moins les données subissent de modifications, plus leur déduplication et leur compression sont faciles et rapides. Chaque modification apportée aux données et enregistrée sur le disque nécessite un cycle d’examen distinct pour identifier les ensembles de données en double et exécuter l’algorithme de compression. Cela augmente ensuite la surcharge du serveur.
- Fréquence de sauvegarde des données : comme indiqué précédemment, en particulier dans le cas de sauvegardes complètes, plus la fréquence de sauvegarde est élevée, plus les données générées sont redondantes. La déduplication et de la compression entraînent donc une plus grande économie d’espace.
L’efficacité de la déduplication et de la compression peut être mesurée comme le rapport entre la taille des données brutes d’origine et leur taille réduite. Par exemple, avec un taux de déduplication de 10:1, 100 Go de données brutes ne nécessitent que 10 Go de capacité de stockage, d’où une économie d’espace de 90 %. Plus le ratio est élevé, plus grandes sont les économies de capacité réalisées. Cela dépend de la capacité du logiciel à effectuer la déduplication et la compression, ainsi que des autres facteurs mentionnés ci-dessus.
La solution software-defined de stockage par blocs DataCore SANsymphony prend en charge la déduplication et la compression à la fois en ligne et post-traitement. Contactez DataCore pour en savoir plus sur SANsymphony et découvrir comment optimiser la capacité de stockage et l’utilisation des ressources.
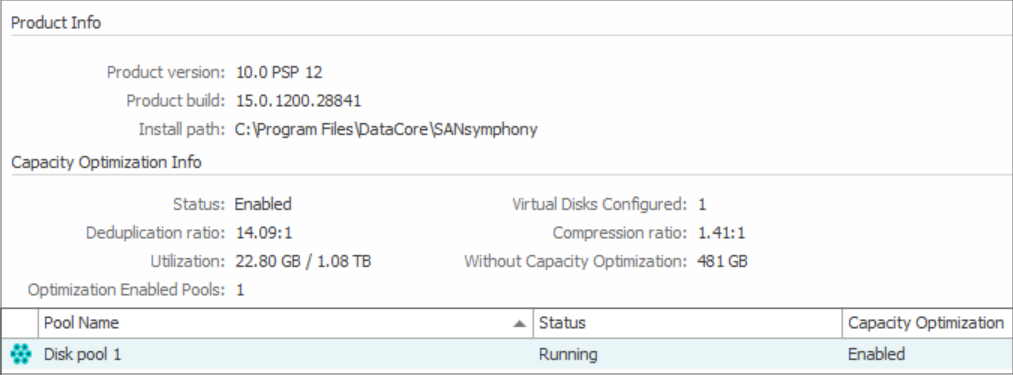
N’oubliez pas que l’efficacité du stockage se reflète directement dans les performances des applications et la productivité de l’entreprise. Le choix de la méthode souhaitée, en ligne ou par post-traitement, dépend en fin de compte des cas d’utilisation de chaque organisation et de l’infrastructure de celle-ci. Les deux méthodes peuvent aussi être utilisées en complément l’une de l’autre dans le même environnement de stockage (quoique dans des pools de stockage distincts).
