
Quando enormi set di dati, infrastrutture frammentate e workload ad alta velocità di trasmissione dati si scontrano, mettono a dura prova i sistemi di storage tradizionali. E questo è particolarmente vero per gli ambienti con un'elevata quantità di dati, come l'AI, l'HPC, i media e la ricerca, dove la gestione del flusso di dati tra tier, siti e cloud diventa un enorme collo di bottiglia.
Ngenea risolve questo problema inserendo automazione intelligente tra le applicazioni e i livelli di storage. Unifica lo storage eterogeneo in un namespace globale, consente un tiering trasparente e orchestra le azioni del ciclo di vita senza interrompere i flussi di lavoro o compromettere le prestazioni. Se utilizzato insieme a DataCore Pixstor, Ngenea migliora le sue capacità con la mobilità intelligente dei dati, estendendo il file system ad alte prestazioni in un data fabric dinamico e basato su policy.
- Estende lo storage esistente con l'orchestrazione; niente soluzioni usa e getta
- Come target, supporta file, object e cloud: NAS, S3, nastro e altro ancora
- Crea un namespace globale con stubbing dei file per un accesso ai dati trasparente
- Automatizza posizionamento, richiamo, migrazione e archiviazione dei dati
- Si integra con gli scheduler di processo e i flussi di lavoro ibridi
- Consente la sincronizzazione e il recupero dei dati tra sedi diverse
- Fornisce l'indicizzazione completa dei metadati e il controllo basato su API
- Deployment on-premise, nel cloud o in ambienti ibridi
Casi d'uso
Ambienti HPC ibridi che richiedono uno spostamento trasparente dei dati tra tier di calcolo, scratch e archivio
Pipeline di addestramento di modelli AI che richiedono ingestione rapida dei dati, pre-staging e archiviazione dei checkpoint
Flussi di lavoro multimediali che richiedono uno spostamento continuo dei dati tra i tier di produzione, rendering, archiviazione e cloud
Collaborazione globale con accesso remoto ai dati tramite una vista unificata e richiamo intelligente delle informazioni
Cloud bursting e DR con caching intelligente, prefetch e trasferimento dei dati a costi ottimizzati
Team multi-sede con accesso distribuito ai dati e governance completa del ciclo di vita
Funzionalità
Ngenea astrae tutto lo storage in un'unica vista logica, eliminando i silos e consentendo il tiering e il richiamo automatizzati e basati su policy tra tier e posizioni diverse.
- Namespace basato su stub con richiamo trasparente all'accesso
- Spostamento dei dati basato su policy in base a età, percorso, tag, accesso, utilizzo
- Tiering tra NVMe, SSD, HDD, object, nastro, cloud, NAS
- Idratazione dei file on-demand o prefetch tramite integrazione con scheduler di processo
- Mantiene i metadati, le autorizzazioni e i percorsi originali
- Funziona con storage legacy tramite stubbing inverso
- Non è necessaria alcuna riconfigurazione di app o utenti
Automatizza lo spostamento dei dati tra livelli di prestazioni e capienza in base all'utilizzo reale, alle policy e ai flussi di lavoro senza influire sull'accesso o interrompere i percorsi.
- Tiering basato su regole per età, dimensioni, proprietario, posizione, tag o attività
- Spostamento trasparente dei dati tra NVMe, SSD, HDD, object, nastro e cloud
- Mantiene percorsi dei file, autorizzazioni e metadati
- Richiamo (idratazione) dei file on-demand o basato su policy in base alle esigenze
- Si integra con i gestori di flussi di lavoro e gli scheduler dei processi
- Lo stubbing inverso consente l'accesso ai dati legacy, riducendo la migrazione
- Allinea il tiering agli obiettivi di prestazioni, costi e conservazione dei dati
- Controllo granulare per scenari di staging, archiviazione o bursting
- Gli strumenti di analisi della capienza forniscono informazioni dettagliate sui modelli di utilizzo per pianificare le decisioni di tiering in modo più efficace
Ngenea tiene traccia dei metadati e li indicizza su tutto lo storage connesso, fornendo visibilità e fruibilità complete indipendentemente dalla posizione fisica.
- Indice centrale di nomi di file, percorsi, tag, marche temporali
- Supporta metadati standard e personalizzati, migliorando la ricercabilità e la visibilità dei dati
- Accesso GUI e API per cercare, filtrare e recuperare i risultati
- Proxy di anteprima disponibili per dati archiviati o "freddi"
- Integrato con Pixstor Search e pipeline esterne
- Esporta i risultati della ricerca in flussi di lavoro operativi
Ngenea accelera spostamento e replica tra ambienti diversi senza la complessità dei trasferimenti manuali o di un'infrastruttura dedicata.
- Sincronizzazione efficiente con impatti minimi
- Opzioni di sincronizzazione bidirezionale e disidratata (solo stub)
- Supporta tipologie di sincronizzazione POSIX↔POSIX, POSIX↔S3 ed S3↔S3
- Trasferimenti ottimizzati in base alla larghezza di banda e controllo per singolo percorso
- Reverse recall ottimizzato per il DR: recupera solo ciò che serve
- Può migrare miliardi di file con facilità
Ngenea si integra con i flussi di lavoro computazionali per automatizzare le azioni di preparazione, staging e post-elaborazione dei dati.
- API REST e Python per trigger pre/post job
- Supporta le toolchain Slurm, Portable Batch System (PBS) e CI/CD
- Trigger basati su file ed eventi per un'automazione completa
- Carica i dati nell’area di scratch prima dell’esecuzione di un processo e li archivia al termine
- Modello di action cart per la movimentazione o la pulizia pianificata
Ngenea garantisce un accesso sicuro e vincolato alle policy in tutti i tier e le posizioni, senza influire sulla produttività degli utenti.
- Controllo degli accessi basato su ruoli (RBAC) a tutti i livelli
- Supporta l'autenticazione AD, LDAP, OAuth2
- Registrazione di audit per gli eventi di richiamo, spostamento e accesso ai dati
- Applicazione delle politiche di conservazione tramite snapshot e policy di tiering
- Crittografia in transito (TLS/SSH) e, opzionalmente, at rest
- Regole specifiche del sito, limiti di richiamo e disponibilità del DR
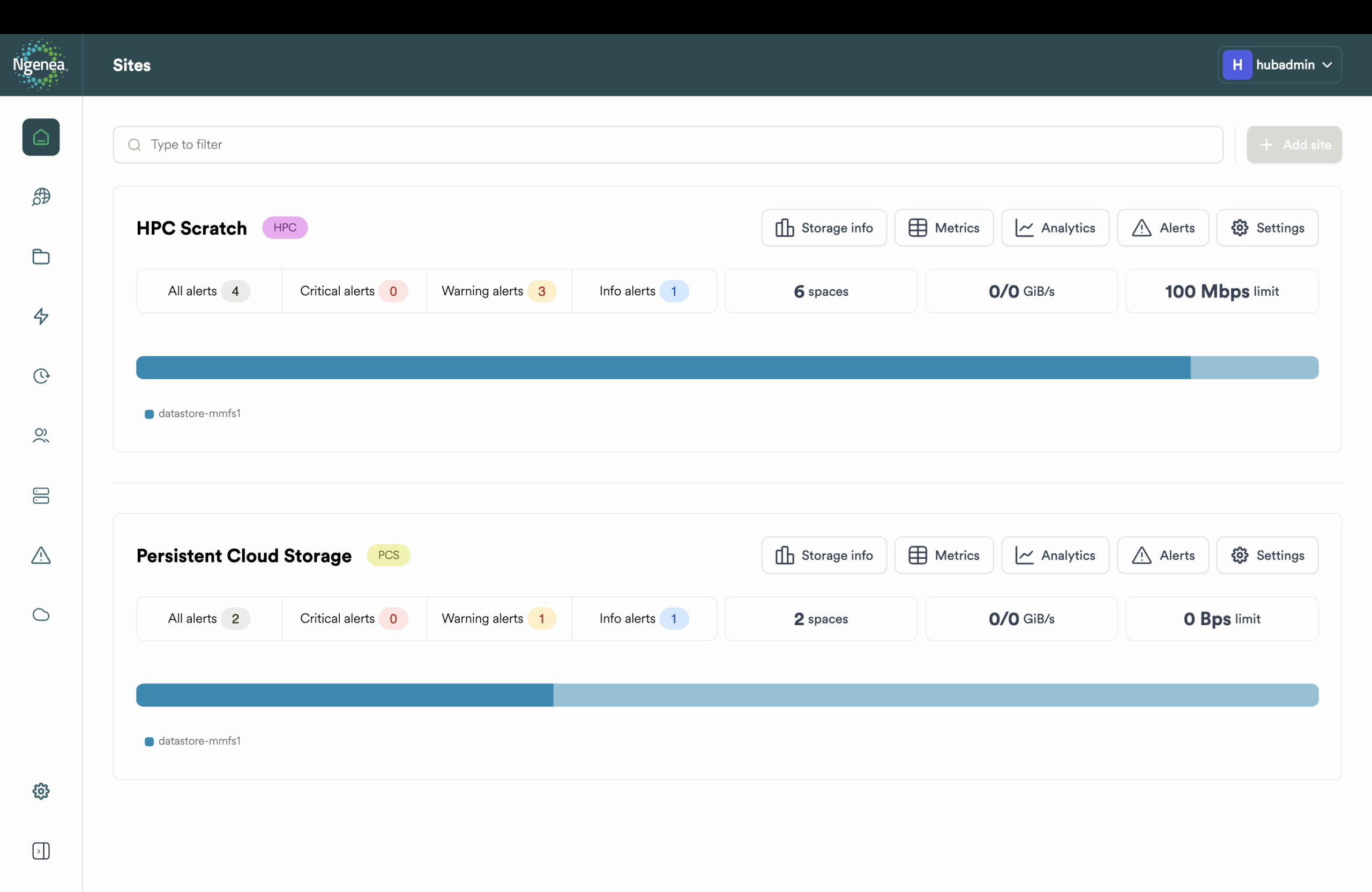
Ngenea garantisce visibilità completa sui dati – dalla dashboard al controllo programmatico – mostrando dove si trovano, come vengono utilizzati e quali costi generano.
- Dashboard centralizzata per lo stato delle policy, la coda di recall e l’utilizzo
- Raccolta e registrazione di eventi e log di sistema tramite Logstash ed Elasticsearch
- Avvisi via e-mail per soglie critiche ed eventi di sistema
- Automazioni predefinite per le azioni legate al ciclo di vita e alle policy
- REST API per l'integrazione e l'orchestrazione
- Trigger personalizzati per ingestione, sincronizzazione, migrazione e DR
Ngenea estende l’orchestrazione a qualsiasi destinazione — dal cloud hyperscale all’archiviazione a lungo termine, fino ai siti di ingestione distribuiti all’edge.
- Si integra con AWS, Azure, GCP e object store privati
- Si integra con DataCore Swarm per l'archiviazione S3 on-premise
- Supporta il nastro tramite BlackPearl e il NAS tramite NFS/S3
- Richiamo trasparente basato su stub e indicizzazione su tutti i target
- Caching e archiviazione in cloud controllati da policy
- Tiering basato su policy in funzione di costi, utilizzo o flussi di lavoro
- Supporta ambienti ibridi e multi-cloud

Collaborazione globale
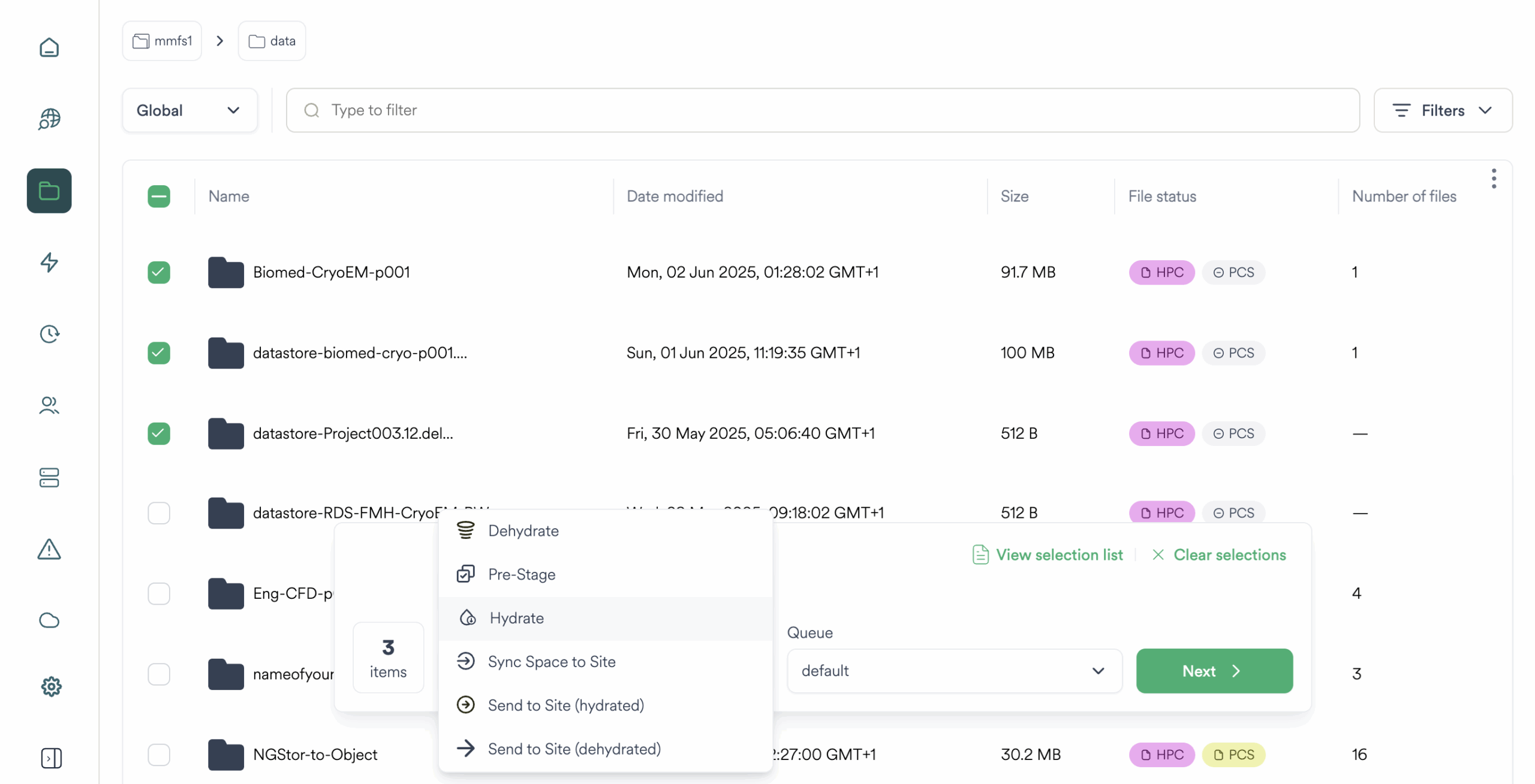
Gestione dei dati basata su policy
Namespace unificato tra siti & posizioni diverse
Benefici
Automatizza le cose complesse

- Pianifica e attiva i flussi di lavoro sui dati tramite regole e policy, senza intervento manuale
- Orchestra i dati dall’ingestione all’archiviazione senza interrompere l’attività degli utenti
- Riduce il sovraccarico operativo tra le diverse sedi
Ottimizza posizionamento e costi dei dati

- Garantisce che i dati "caldi" rimangano su uno storage veloce; archivia automaticamente i dati "freddi"
- Applica policy basate sui costi per evitare spese cloud impreviste
- Sfrutta i sistemi di storage esistenti ed espandi liberamente l’infrastruttura con l’hardware che preferisci: nessun lock-in imposto dai vendor
Abilita la collaborazione globale

- I team remoti lavorano come un’unica squadra attraverso un namespace unificato
- L’accesso tramite stub garantisce che i file siano sempre individuabili
- I dati vengono richiamati su richiesta o precaricati in base alle necessità
- L'accesso basato sui ruoli garantisce che gli utenti vedano solo ciò di cui hanno bisogno
Accelera i workload

- I dati sono dove devono essere anche prima dell'inizio dei processi di calcolo
- Precarica, memorizza in cache e idrata i dati senza ritardi
- Semplifica i flussi di lavoro dal core all'edge, fino al cloud
Protegge & ripristina con precisione

- DR basato su stub con footprint ridotto
- Sincronizzazione e richiamo basati su policy tra tier di storage e siti diversi
- Ripristino rapido senza replica completa del set di dati
Rende la strategia di storage a prova di futuro

- Integrazione semplificata di nuovo hardware, storage o siti
- Esegue il tiering su cloud o nastro senza interrompere i flussi di lavoro
- Scala operatività e sedi senza dover reinventare i meccanismi di accesso
Architettura

Architettura di riferimento DataCore Ngenea e Pixstor per ambienti HPC/AI
Deployment
Il deployment di Ngenea e Pixstor può essere realizzato on-premise, nel cloud o come soluzione ibrida, offrendo la flessibilità necessaria per supportare qualsiasi flusso di lavoro o strategia infrastrutturale.
Licensing
Ngenea è concesso in licenza in base al numero di server. Una singola licenza consente lo spostamento dei dati su un qualsiasi numero di destinazioni di storage — tra cui scratch, home, archivio e cloud — senza limiti di capienza e senza costi basati sulle prestazioni. In questo modo si eliminano i costi nascosti, si evitano tariffe basate sulla capienza man mano che il namespace si espande ed è possibile disattivare o riutilizzare l'hardware senza incorrere in costi di licenza aggiuntivi. Ngenea è disponibile esclusivamente in abbinamento a Pixstor.