
I flussi di lavoro ad alta intensità di dati si interrompono sotto pressione quando lo storage tradizionale non riesce a tenere il passo. Che si tratti di addestramento dell'AI, simulazioni HPC o di progetti multimediali ad alta risoluzione, i colli di bottiglia delle prestazioni, la frammentazione del file system e il sovraccarico dei metadati possono arrestare i progressi.
Pixstor è un filesystem scalabile (scale-out) ad alte prestazioni, definito dal software, dotato di funzionalità NAS. Garantisce una velocità di trasmissione costante, una bassa latenza e un accesso multiprotocollo senza interruzioni, supportando carichi di lavoro misti, un numero elevato di file e casi d'uso esigenti senza compromessi. Grazie al tiering intelligente dei dati e a uno spazio dei nomi unificato, Pixstor semplifica la gestione assicurando al contempo che i dati siano sempre veloci, accessibili e sicuri.
- Supporta qualsiasi tecnologia di storage: NVMe, SSD, SAS, NL-SAS e così via
- support diversi protocolli support SMB, NFS, SFTP, POSIX, S3 e NVMe
- Scala da ambienti terabyte a multi-petabyte con miliardi di file
- Garantisce prestazioni fino a 180 GB/s in un formato 4U
- Progettato per garantire prestazioni ottimali anche con un utilizzo della capacità pari al 99%
- Consente accesso rapido ai dati, ricerca dei file e controllo del ciclo di vita
- Deployment on-premise o nel cloud, con supporto per flussi di lavoro ibridi
Casi d'uso
Workload HPC che richiedono un'elaborazione rapida e parallela e l'accesso a set di dati di grandi dimensioni a velocità di I/O estreme
Ambienti di addestramento AI/ML che richiedono un accesso rapido e a bassa latenza a set di dati di grandi dimensioni da cluster GPU
Workload per le scienze biologiche e la genomica, con processi paralleli di sequenziamento, scansione e analisi
Editing video con elevata velocità di trasferimento dati e rendering VFX in pipeline multimediali e di intrattenimento
File system sicuro e multi-tenant per team creativi o gruppi di ricerca con accesso e quote controllati
Organizzazioni che sostituiscono NAS legacy o file system scalabili orizzontalmente che non sono in grado di mantenere le prestazioni su larga scala
Funzionalità
Pixstor è un file system parallelo ad alte prestazioni, conforme a POSIX, pensato per gestire miliardi di file in modo preciso, efficiente e sotto pieno controllo. Il suo namespace globale unificato e l'architettura di metadati distribuita eliminano i colli di bottiglia supportando al contempo ambienti a protocollo misto su larga scala.
- Namespace unificato per tutti i tipi di disco, tier e posizioni
- Policy a livello di file per quote, ACL, snapshot e metadati
- Accesso multiprotocollo simultaneo: NFS, SMB, SFTP, POSIX, S3
- Supporta NVMe-oF e GPUDirect per percorsi dati ultra veloci e a bassa latenza dallo storage ai nodi di calcolo e alle GPU
- Isolamento del namespace attraverso la segmentazione logica a livello di progetto (per esempio, Fileset)
- Caching locale che accelera l’accesso ai dati “caldi” o frequentemente riutilizzati
- Supporto nativo per miliardi di file e directory
- Ottimizzato per blocchi di grandi dimensioni, fino a 8 MB, senza compromettere le prestazioni con i file di piccole dimensioni
Pixstor automatizza il posizionamento intelligente dei dati con policy di tiering granulari che spostano i dati tra i livelli di prestazioni e capienza senza interrompere i flussi di lavoro o le autorizzazioni di accesso.
- Tiering basato su policy in base all'età, alle dimensioni, all'ora di accesso, alla posizione, al proprietario o ai tag dei file
- Classificazione trasparente tra NVMe, SSD e HDD, estendibile allo storage a oggetti, cloud pubblico, ai nastri e ad altri sistemi di archiviazione grazie a DataCore Ngenea
- Spostamento trasparente dei dati mantenendo percorsi di accesso e autorizzazioni
- Quando vi si accede, i file vengono richiamati in modo trasparente dai tier inferiori
Le snapshot e i cloni in Pixstor sono leggeri e costruiti per la scalabilità, consentendo un rollback rapido, ambienti di test e scenari di ripristino completo tra i siti.
- Snapshot copy-on-write con impatto minimo sulle prestazioni
- Cloni di snapshot scrivibili per flussi di lavoro di staging, test o temporanei
- Integrazione delle Versioni Precedenti di Windows per punti di ripristino accessibili dall'utente
- Conservazione delle snapshot con versione nelle destinazioni di backup
- Set di backup montabili per l'accesso immediato al DR
- Replica site-to-site e sincronizzazione del DR utilizzando la tecnologia snapshot-diff
Il motore di ricerca di Pixstor va oltre i nomi dei file per consentire deep discovery, aggiunta di tag e automazione utilizzando metadati e analisi dei contenuti su tutti i tier, anche offline o su set di dati archiviati.
- Indicizzazione integrata di metadati e contenuti con Pixstor Search
- Indicizzazione degli attributi dei file (nome, dimensione, proprietario), del contenuto (EXIF, testo) e dei tag AI/ML
- Aggiunta di tag personalizzati ai metadati tramite attributi estesi (xattrs)
- Ricerca e anteprima su dati aggiornati in tempo reale, archiviati e remoti
- Risultati esportabili per flussi di lavoro editoriali o di pre-staging
- Carrello di ricerca attiva: cerca → seleziona → agisci (copia, sposta, archivia)
- Accessibile tramite interfaccia web o API programmabile
Pixstor ottimizza l'utilizzo dello storage con la compressione in linea e la logica di deduplica intelligente che identifica i contenuti ridondanti e ne riduce l'ingombro senza influire sulle prestazioni.
- Compressione in linea al momento della scrittura
- Decompressione trasparente in fase di lettura
- Identificazione basata su policy dei file duplicati in base ai risultati della ricerca
La sicurezza è integrata in Pixstor a ogni livello, dall'accesso basato sui ruoli alla crittografia e alla segmentazione a livello di tenant, garantendo che i dati siano sempre protetti e conformi.
- Controllo degli accessi in base al ruolo (RBAC) per una gestione granulare degli utenti
- Container NAS sicuri con dati completi, metadati e isolamento degli accessi
- Autenticazione tramite Active Directory, LDAP, OKTA e OAuth2
- Policy di immutabilità e conservazione dei dati che utilizzano snapshot e applicazione delle ACL
- Rollback basato su snapshot per scenari di ripristino e audit
- TLS, crittografia SSH in transito e crittografia opzionale at rest
- Isolamento per tenant per l'accesso, i percorsi di rete e gli ambiti di applicazione delle policy
Pixstor consente una replica veloce e scalabile tra diverse sedi, permettendo di eseguire backup con versioni successive e trasferimenti di grandi volumi, il tutto senza colli di bottiglia legati alla struttura ad albero.
- Replica basata sul snapshot per una sincronizzazione veloce e incrementale dei dati
- I set di backup con versioni possono essere montati istantaneamente per consentire un accesso rapido o il ripristino in caso di emergenza
- snapshots con versionesupport a punti specifici nel tempo
- Opzioni di sincronizzazione tra siti: unidirezionale, bidirezionale o a più livelli
- Motore di trasferimento multithread e multinodo per la replica ad alte prestazioni
- Ripristino self-service tramite puntiSMB standard
- support completo support gli ACL di Windows, VSS e le autorizzazioni NTFS
Pixstor include osservabilità e automazione integrate, offrendo visibilità e controllo completi dalla dashboard alla CLI fino ai flussi di lavoro programmatici.
- Metriche in tempo reale per larghezza di banda, latenza, CPU e lunghezza della coda
- Analisi I/O per client e a livello di protocollo
- Logstash/Elasticsearch integrati per eventi e avvisi
- Log centralizzati e audit trail per eventi e operazioni sui file
- Notifiche e-mail per eventi e soglie di sistema
- Hook di automazione basati su file (per esempio, il rilascio di un file attiva un processo)
- SaltStack per la configurazione del sistema e il controllo della versione
- Automazione del ciclo di vita tramite interfaccia web, REST API e Python SDK
- Compatibile con gli scheduler di workload come Slurm tramite accesso POSIX/NFS
Pixstor supporta i flussi di lavoro cloud quando integrato con Ngenea, consentendo una suddivisione in livelli trasparente, la ricerca e la gestione dei dati basata su criteri sia cloud on-premise che cloud .
- Accesso agli oggetti compatibile con S3, compresa l'integrazione nativa con DataCore Swarm
- Tiering trasparente da e verso AWS, Azure, GCP e altri object store
- Flussi di lavoro ibridi con caching intelligente e logica push/pull
- Ricerca e anteprima tra tier cloud e on-premise
- Hook di policy per applicare l’uso dei tier in base a costi e regole di conservazione
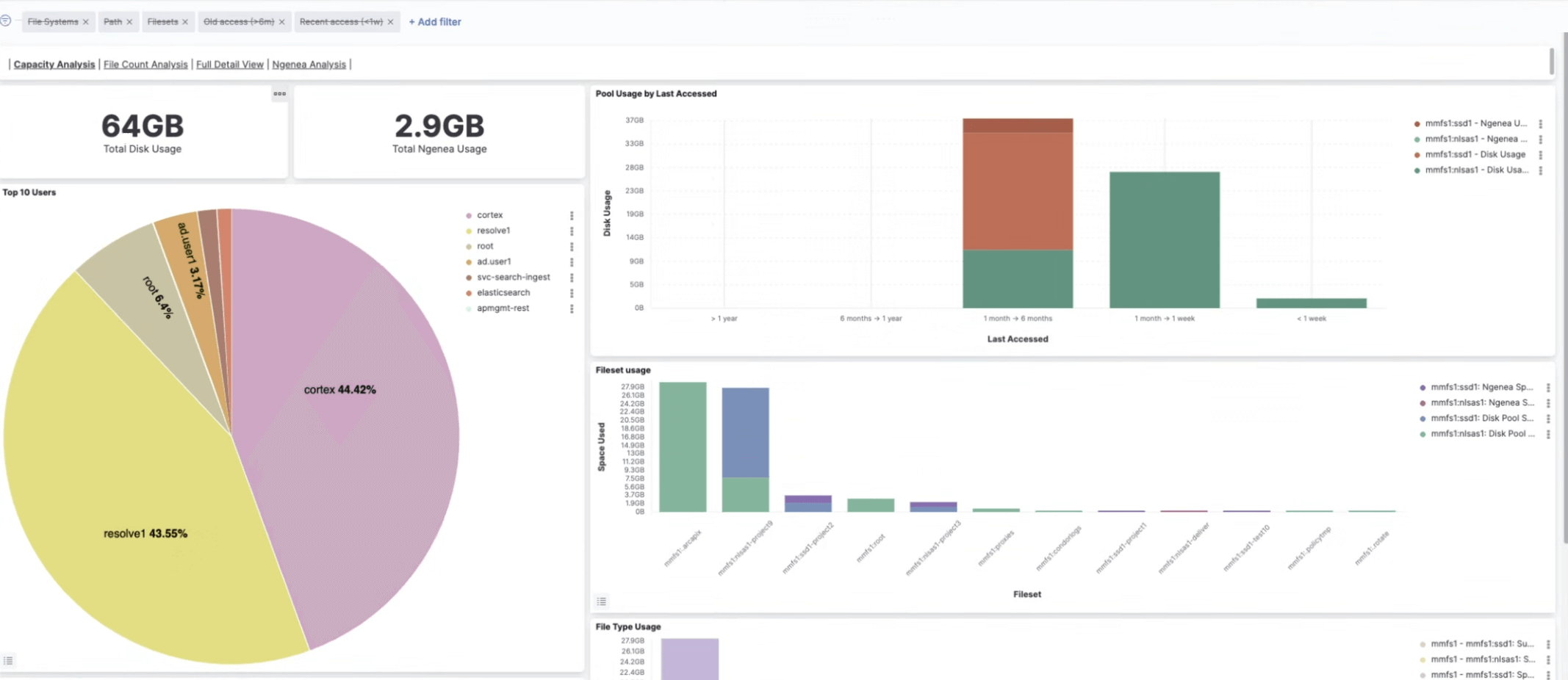
Analisi dell'utilizzo dei file
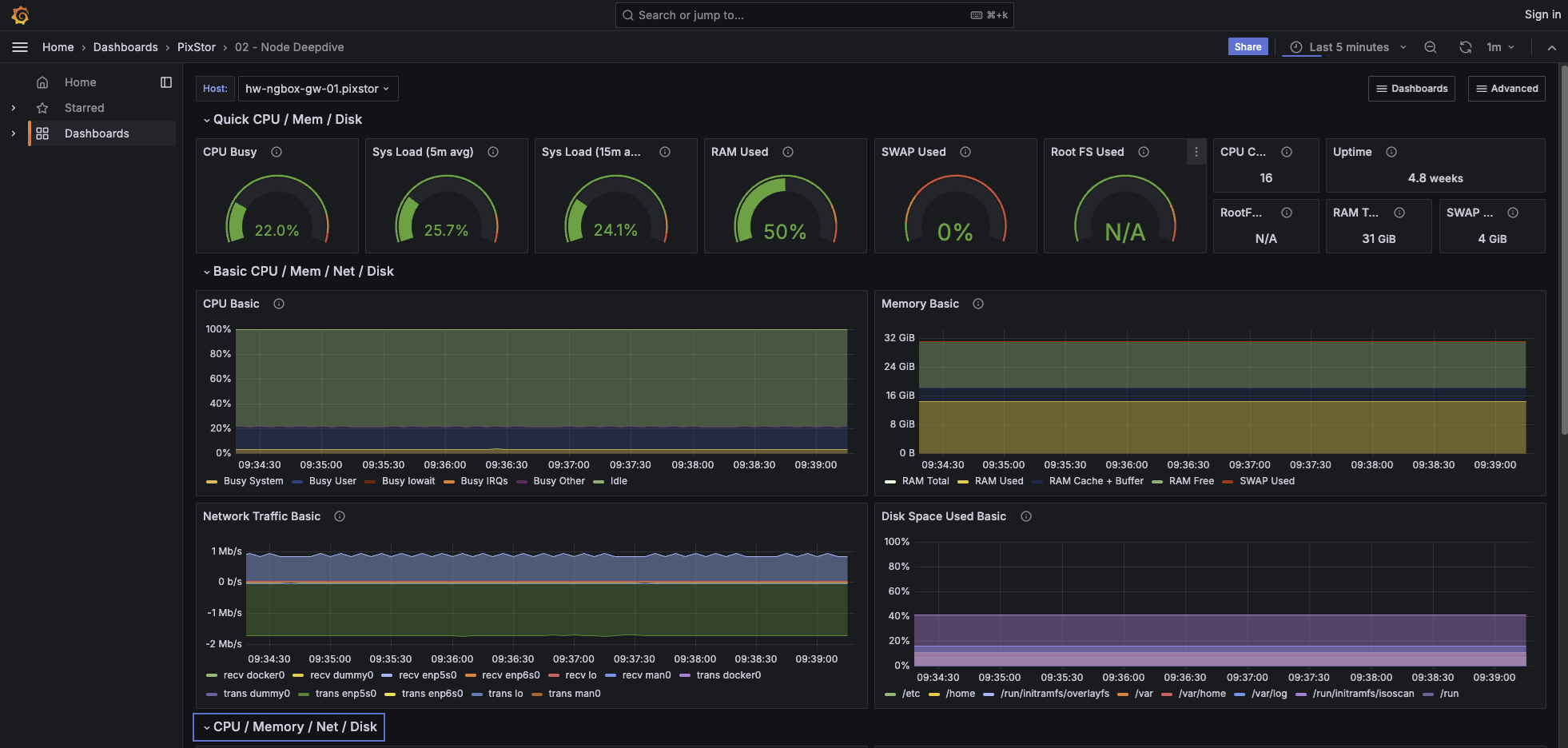
Osservabilità e monitoraggio
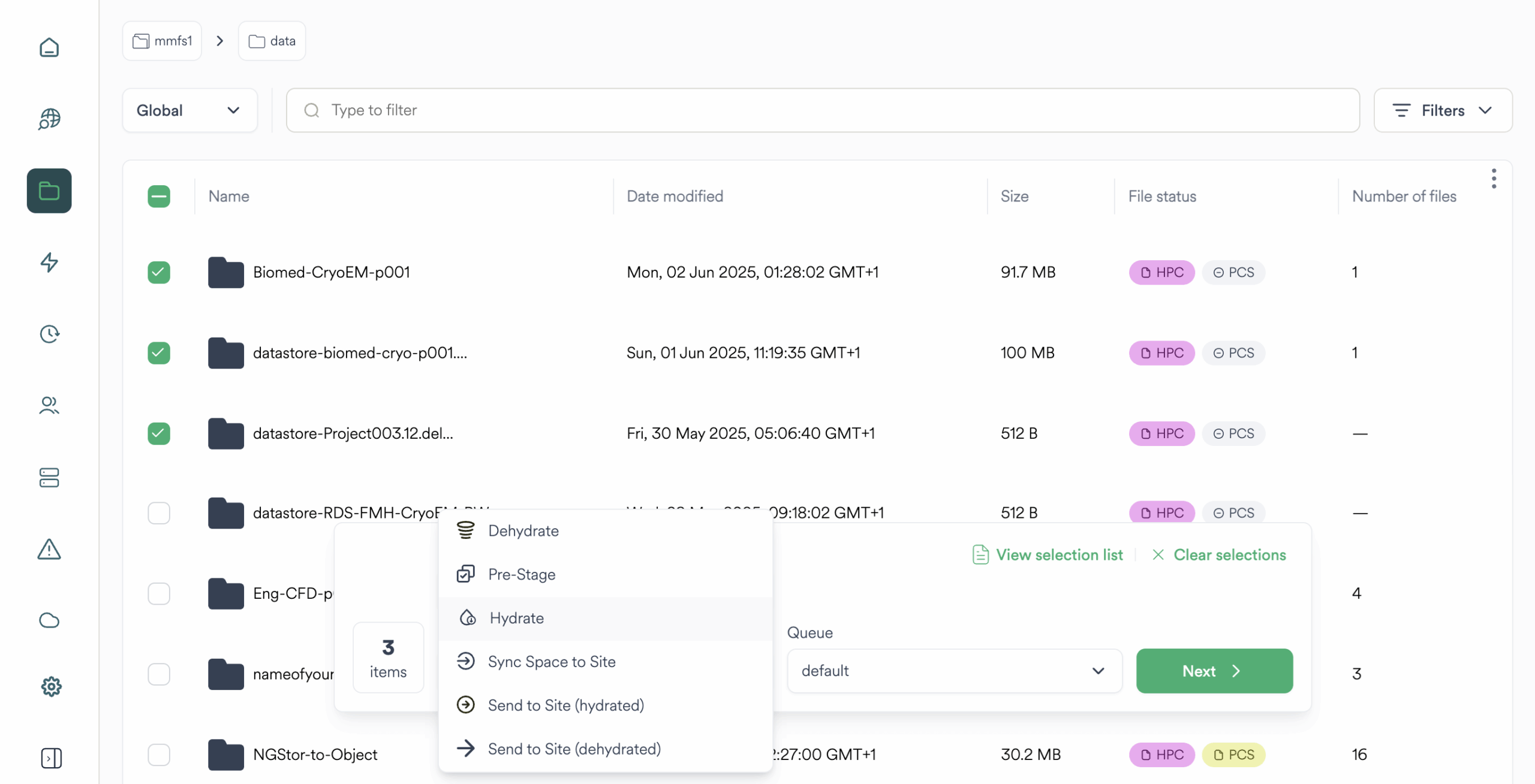
Con Ngenea, gestione dei dati basata su policy
Benefici
Accelera i tempi di ottenimento dei risultati

- Riduce i ritardi di avvio del processo con l'accesso istantaneo ai set di dati
- Precarica i dati in modo intelligente per i flussi di lavoro di calcolo
- Elimina i colli di bottiglia legati allo storage nelle pipeline critiche
Lavora in modo più intelligente con l'automazione

- Imposta e dimentica le policy del ciclo di vita in base all'utilizzo reale
- Sposta automaticamente i dati tra storage veloce e profondo
- Riduci la gestione manuale dei file e le attività basate su supposizioni
Trova ciò che cerchi, velocemente

- Niente più ricerche tra i sistemi: una visione unificata di tutti i file
- Ricerca per progetto, utente o tag anche se i dati sono archiviati
- Ricerca attiva: copia, sposta, archivia in un solo passaggio
Costi più bassi senza compromessi

- Mantieni lo storage costoso concentrato sui dati attivi
- Massimizza il ROI utilizzando hardware di base
- Costi chiari e prevedibili: paghi solo ciò che utilizzi, scali liberamente in base alle necessità e senza sorprese o costi nascosti
Protegge i dati senza rallentamenti

- Snapshot e DR integrati nativamente, non semplici componenti aggiuntivi
- Mantiene gli utenti produttivi garantendo al contempo la conformità
- Ripristina rapidamente i file senza necessità di chiamare l'IT
Si collega a qualsiasi flusso di lavoro

- Funziona con le app, i flussi di lavoro e l'infrastruttura esistenti
- Si integra con gli scheduler di processo e le pipeline
- Nessun lock-in imposto dai vendor: i dati rimangono sotto controllo
Architettura

Architettura di riferimento di DataCore Nexus (Pixstor e Ngenea) per ambienti HPC/AI
Deployment
Pixstor e Ngenea sono disponibili sotto forma di appliance chiavi in mano completamente integrata denominata Nexus. Ogni appliance Nexus include i componenti Pixstor necessari, quali nodi di archiviazione, nodi gateway e nodi di gestione, insieme ai servizi di orchestrazione Ngenea, il tutto fornito in un modello di appliance semplificato. Questa architettura compatta e convergente offre una base scalabile e flessibile per flussi di lavoro ad alte prestazioni e la gestione dei dati.
Licensing
La licenza si basa su due fattori chiave: il numero di appliance Nexus implementate e la capacità totale utilizzabile di Pixstor nella soluzione. Le funzionalità di Ngenea possono essere aggiunte all’appliance in base alle esigenze. I dati trasferiti da Ngenea tra livelli di storage esterni (come lo storage a oggetti, cloud, i nastri, ecc.) non vengono conteggiati ai fini della licenza e non comportano costi aggiuntivi. Questo modello offre una scalabilità prevedibile senza sovrattasse legate ai livelli di prestazioni né costi nascosti per le licenze dell’infrastruttura, consentendo al contempo un’espansione flessibile delle capacità di storage, orchestrazione e gestione dei dati man mano che le esigenze crescono.