La maggior parte dei data center utilizza diverse categorie di supporti di storage, come dischi SATA, dischi SAS e SSD/Flash. Ciascuna categoria può avere molte sotto-categorie diverse, in particolare gli SSD/Flash, e tutte differiscono in termini di velocità di accesso, capienza e prezzo. I dati a cui si accede più frequentemente dovrebbero restare sui supporti di storage più veloci, ma questi sono anche i più rari, perché sono costosi.
Che cos'è l'auto-tiering
L'auto-tiering consente di archiviare, e successivamente leggere, i dati sul supporto di archiviazione più adatto in base a regole o criteri predefiniti. Questo approccio alle classi di dati con archiviazione a più livelli individua automaticamente quali set di dati sono maggiormente consultati dalle applicazioni (i dati "hot") e li colloca sullo storage più veloce. Lo stesso vale per i dati "warm" e "cold", che vengono automaticamente collocati su storage di secondo livello o di livello inferiore. Tutto ciò avviene in modo dinamico e in tempo reale, pur rimanendo invisibile in background. A seconda dell’utilizzo dei dati, la classificazione può cambiare automaticamente di livello, consentendo di ottenere le migliori velocità per le informazioni mission-critical e business-critical. Esplora le funzionalità riportate di seguito per scoprire come massimizzare la velocità delle applicazioni in tutta l’organizzazione e adattare l’infrastruttura di archiviazione alle esigenze aziendali.

Tiering vs Caching: ecco la differenza
A prima vista, le soluzioni di tiering e di caching possono sembrare simili, ma ci sono differenze fondamentali nell'utilizzo dello storage più veloce e nella tecnologia sottostante utilizzata per identificare e velocizzare i dati a cui si accede più frequentemente.

L'High-Speed Caching è un algoritmo di caching proprietario che accelera I/O la RAM come cache di lettura e scrittura. DataCore supporta fino a 8 TB di cache ad alta velocità per nodo, creando una vera e propria “mega-cache” in grado di potenziare notevolmente le prestazioni delle applicazioni.
La RAM è un componente di base e quindi relativamente economico, anche se possiede caratteristiche prestazionali eccezionali e non è afflitta dai punti deboli attribuiti ai dispositivi Flash. La RAM è una tecnologia eccellente da sfruttare per accelerare le prestazioni dell'I/O e offrire un rapporto tra benefici e costi molto elevato sull'intera architettura di storage.
Il caching ad alta velocità è fondamentale per mantenere le prestazioni delle applicazioni, poiché la RAM è di molti ordini di grandezza più veloce Flash più veloci e si trova il più vicino possibile alla CPU. È il componente di archiviazione più veloce dell'architettura, in grado di garantire un aumento delle prestazioni delle applicazioni da 3 a 5 volte superiore e di liberare i server applicativi affinché possano svolgere altre attività. Inoltre, prolunga la durata dei componenti di archiviazione tradizionali riducendo al minimo lo stress causato dal thrashing del disco.
I carichi di lavoro delle applicazioni sono difficili da prevedere. L'Auto-Tiering è un meccanismo intelligente in tempo reale che assegna continuamente i dati alla classe di storage più appropriata in base alla frequenza con cui vengono consultati. Il risultato è una performance superiore delle applicazioni e un TCO inferiore nell'intera architettura di storage.
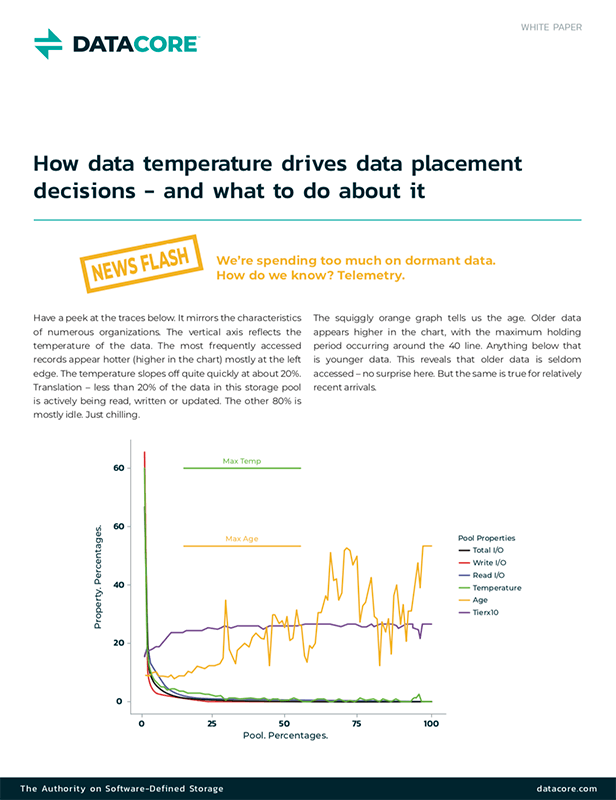
Lo storage a più livelli evita la necessità di effettuare ingenti investimenti nella costosa Flash . Le statistiche di settore mostrano che, in media, solo il 15-20% dell’intero volume di dati di un’azienda beneficia dello Flash , poiché la percentuale restante è considerata in gran parte inattiva.
Secondo Gartner, "Gli schemi di accesso, il valore e le caratteristiche d'uso dei dati memorizzati su array di storage variano moltissimo, e dipendono dai cicli aziendali e dalle procedure organizzative. A causa dell'estrema variabilità, i dati memorizzati su questi dispositivi non possono essere salvati in modo efficiente sulla stessa tipologia, tier, formato o supporto di storage."

L'Auto-Tiering sfrutta qualsiasi combinazione di tecnologie Flash a disco tradizionali, sia interne che basate su array, support a 15 diversi livelli di archiviazione. Ad esempio:
| Tier | Caratteristiche | % DELLA PRODUZIONE TOTALE |
| 1 | Dischi ultra-veloci (flash) | 15% |
| 2 | Disco ad alta velocità (SAS 15k) | 25% |
| 3 | Disco di capacità (SAS 7,2k NL) | 60% |
| 4 | Dischi per test/sviluppo (SATA) | Secondo necessità |
| 5 | Dischi cloud per archiviazione | Secondo necessità |
Con l'arrivo di nuove tecnologie avanzate per i dischi, i tier di storage esistenti possono essere modificati in base alle esigenze e nuovi tier possono essere aggiunti diversificando ulteriormente l'architettura di storage.
I benefici principali dell'auto-tiering
- Analisi dinamica dei dati: monitoraggio in tempo reale degli schemi di accesso ai dati per un posizionamento ottimale sui tier
- Migrazione trasparente: spostamenti automatizzati e senza interrompere l'erogazione dei servizi tra i tier di storage
- Coerenza tra dispositivi: funzionalità di auto-tiering uniformi su dispositivi di fornitori diversi
- Utilizzo efficiente dello spazio: massimizzazione della capienza di storage grazie al posizionamento ottimale dei dati
- Completamente automatizzato: configuralo e lascia che l'automazione faccia il resto: non è necessario alcun intervento manuale.
Adaptive Data Placement: amplifica l'efficacia dell'auto-tiering
Nel campo dello storage a blocchi, l’ottimizzazione della capacità è un requisito fondamentale per ridurre l’ingombro dello storage tramite la compressione dei dati e l’eliminazione dei segmenti ridondanti. SANsymphony la funzione “Adaptive Data Placement”, che estende la capacità di auto-tiering per operare in sinergia con la deduplicazione e la compressione inline.
SANsymphony analizza continuamente la frequenza di accesso ai dati e la sua "temperatura", individuando i set di dati relativamente freddi e i candidati principali per la compressione e la deduplica. Una volta identificati, questi set di dati vengono ottimizzati per sfruttare al meglio la capienza.
SANsymphony tiene poi traccia in modo dinamico degli schemi di accesso ai dati, utilizzando l'auto-tiering per garantire che i set di dati siano sempre collocati sui tier di storage più appropriati, ottimizzando così in tempo reale sia le prestazioni che la capienza: una capacità unica per una soluzione di storage.
Il risultato? Ottieni:
- Le migliori prestazioni possibili per i dati caldi
- Il più basso ingombro possibile per i dati freddi

