La maggior parte dei data center utilizza diverse categorie di supporti di storage, come dischi SATA, dischi SAS e SSD/Flash. Ciascuna categoria può avere molte sotto-categorie diverse, in particolare gli SSD/Flash, e tutte differiscono in termini di velocità di accesso, capienza e prezzo. I dati a cui si accede più frequentemente dovrebbero restare sui supporti di storage più veloci, ma questi sono anche i più rari, perché sono costosi.
Che cos'è l'auto-tiering
L'auto-tiering consente di archiviare i dati, e successivamente di leggerli, sul supporto di storage più adatto in base a regole o policy predefinite. Questo approccio ai dati basato su classi di storage suddivise per livelli consente di individuare automaticamente i set di dati a cui le applicazioni accedono più di frequente (dati caldi) e di posizionarli sullo storage più veloce. Lo stesso vale per i dati "tiepidi" e "freddi", che vengono posizionati automaticamente su storage di secondo livello o inferiore. Tutto questo processo, pur rimanendo invisibile, avviene dinamicamente in tempo reale. A seconda dell'utilizzo dei dati, la classificazione può essere automaticamente spostata verso l'alto o verso il basso, consentendo di ottenere le migliori velocità per le informazioni mission e business-critical. Guarda qui sotto le funzionalità di cui parliamo e scopri come massimizzare la velocità delle applicazioni nell'intera organizzazione personalizzando l'infrastruttura di storage in base alle esigenze aziendali.

Tiering vs Caching: ecco la differenza
A prima vista, le soluzioni di tiering e di caching possono sembrare simili, ma ci sono differenze fondamentali nell'utilizzo dello storage più veloce e nella tecnologia sottostante utilizzata per identificare e velocizzare i dati a cui si accede più frequentemente.

L'High-Speed Caching è un algoritmo di caching proprietario che accelera l'I/O sfruttando la RAM come cache di lettura e scrittura. DataCore supporta fino a 8TB di cache ad alta velocità per nodo, creando una "mega cache" capace di mettere il turbo alle prestazioni applicative.
La RAM è un componente di base e quindi relativamente economico, anche se possiede caratteristiche prestazionali eccezionali e non è afflitta dai punti deboli attribuiti ai dispositivi Flash. La RAM è una tecnologia eccellente da sfruttare per accelerare le prestazioni dell'I/O e offrire un rapporto tra benefici e costi molto elevato sull'intera architettura di storage.
L'High-Speed Caching è fondamentale per sostenere le prestazioni applicative, poiché la RAM è di molti ordini di grandezza più veloce delle più rapide tecnologie flash e risiede il più vicino possibile alla CPU. È il componente di storage più veloce di tutta l'architettura, offrendo alle applicazioni un incremento di prestazioni di 3-5 volte e liberando i server applicativi per altri compiti. Allunga anche la vita dei tradizionali componenti di storage minimizzando lo stress dovuto al "disk trashing".
I workload applicativi sono difficili da prevedere. L'auto-tiering è un meccanismo intelligente che in real-time posiziona continuamente i dati sulla categoria di storage più adeguata in base alla frequenza con cui vi si accede. Tutto questo si traduce in prestazioni applicative superiori e in un TCO più basso su tutta l'infrastruttura di storage.
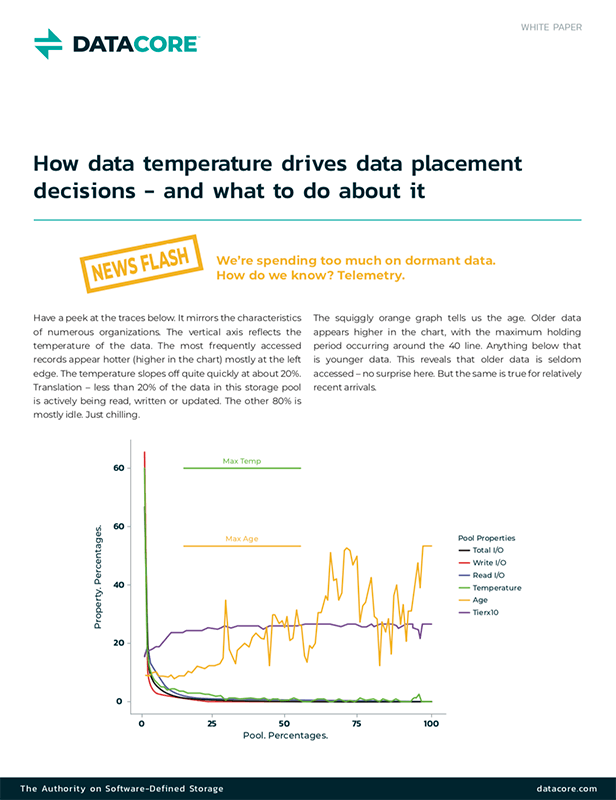
Lo storage tiered evita la necessità di investire pesantemente in costosa tecnologia Flash. Le statistiche di settore indicano che, in media, solo tra il 15 e il 20% del patrimonio aziendale di dati trae beneficio dallo storage flash, poiché la restante parte è considerata per lo più dormiente.
Secondo Gartner, "Gli schemi di accesso, il valore e le caratteristiche d'uso dei dati memorizzati su array di storage variano moltissimo, e dipendono dai cicli aziendali e dalle procedure organizzative. A causa dell'estrema variabilità, i dati memorizzati su questi dispositivi non possono essere salvati in modo efficiente sulla stessa tipologia, tier, formato o supporto di storage."

L'auto-tiering sfrutta una combinazione di tecnologia Flash e dischi tradizionali, indipendentemente dal fatto che siano interni o basati su array, supportando fino a 15 differenti tier di storage. Per esempio:
| Tier | Caratteristiche | % DELLA PRODUZIONE TOTALE |
| 1 | Dischi ultra-veloci (flash) | 15% |
| 2 | Dischi veloci (SAS 15k) | 25% |
| 3 | Dischi a elevata capienza (SAS 7,2k NL) | 60% |
| 4 | Dischi per test/sviluppo (SATA) | Secondo necessità |
| 5 | Dischi cloud per archiviazione | Secondo necessità |
Con l'arrivo di nuove tecnologie avanzate per i dischi, i tier di storage esistenti possono essere modificati in base alle esigenze e nuovi tier possono essere aggiunti diversificando ulteriormente l'architettura di storage.
I benefici principali dell'auto-tiering
- Analisi dinamica dei dati: monitoraggio in tempo reale degli schemi di accesso ai dati per un posizionamento ottimale sui tier
- Migrazione trasparente: spostamenti automatizzati e senza interrompere l'erogazione dei servizi tra i tier di storage
- Coerenza tra dispositivi: funzionalità di auto-tiering uniformi su dispositivi di fornitori diversi
- Utilizzo efficiente dello spazio: massimizzazione della capienza di storage grazie al posizionamento ottimale dei dati
- Completamente automatizzato: configuralo e lascia che l'automazione faccia il resto: non è necessario alcun intervento manuale.
Adaptive Data Placement: amplifica l'efficacia dell'auto-tiering
Nell'ambito del block storage, l'ottimizzazione della capienza è un requisito fondamentale per ridurre l'ingombro dello storage comprimendo i dati ed eliminando i segmenti di dati ridondanti. SANsymphony introduce l'Adaptive Data Placement, che amplifica le capacità di auto-tiering per lavorare in tandem con la deduplica e la compressione in linea.
SANsymphony analizza continuamente la frequenza di accesso ai dati e la sua "temperatura", individuando i set di dati relativamente freddi e i candidati principali per la compressione e la deduplica. Una volta identificati, questi set di dati vengono ottimizzati per sfruttare al meglio la capienza.
SANsymphony tiene poi traccia in modo dinamico degli schemi di accesso ai dati, utilizzando l'auto-tiering per garantire che i set di dati siano sempre collocati sui tier di storage più appropriati, ottimizzando così in tempo reale sia le prestazioni che la capienza: una capacità unica per una soluzione di storage.
Il risultato? Ottieni:
- Le migliori prestazioni possibili per i dati caldi
- Il più basso ingombro possibile per i dati freddi

