
Wenn ein herkömmliches externes Storage-Array nicht ausreicht, dann liegt das in der Regel daran, dass sich die Infrastruktur schneller entwickelt hat als die Datenebene. Jahrelang ging die Branche davon aus, dass Storage eine statische Einheit sei – eine „Black Box“, die außerhalb des Rechenclusters steht. Doch da Red Hat OpenShift zum Eckpfeiler des modernen Rechenzentrums wird, ist diese Trennung nicht mehr nur eine architektonische Nuance, sondern ein Leistungsengpass.
Seit Anfang 2024 hat die Dynamik hinter Red Hat OpenShift ein beispielloses Niveau erreicht. Laut aktuellen Daten von Red Hat ist die Kundenakzeptanz allein von OpenShift Virtualization seit Anfang 2024 um 178 gestiegen%. Produktionsbereitstellungen nehmen deutlich zu, da Unternehmen nach einer stabilen, skalierbaren Alternative zu älteren Hypervisoren suchen. Dieser Wandel wird durch den Bedarf an einer einheitlichen Basis vorangetrieben, die sowohl containerisierte Microservices als auch ältere virtuelle Maschinen verarbeiten kann. Wenn Sie diese Umgebungen jedoch skalieren, stellen Sie schnell fest, dass OpenShift zwar tausend Container in Sekundenschnelle orchestrieren kann, der zugrunde liegende OpenShift-Speicher jedoch oft Mühe hat, Schritt zu halten.
Die OpenShift-Speicherherausforderung: Die „zustandsbehaftete“ Spannung in einer zustandslosen Welt
In der Branche wird oft behauptet, das Container Storage Interface (CSI) sei die universelle Lösung für Kubernetes-Speicher. In der Praxis ist das CSI jedoch lediglich ein Übersetzer. Zwar ermöglicht es OpenShift die „Kommunikation“ mit einem externen Array, trägt aber nichts dazu bei, die grundlegende architektonische Diskrepanz zwischen verteilter Orchestrierung und zentralisiertem Speicher zu beheben.
Das Problem ist nicht nur die Konnektivität, sondern auch die Latenz und das deterministische Verhalten.
Wenn Sie hochleistungsfähige, zustandsbehaftete Workloads – wie PostgreSQL, Kafka oder KI-Trainingspipelines – auf OpenShift ausführen, stoßen Sie auf den sogenannten „I/O-Blender“-Effekt. Herkömmliche SANs sind für die vorhersehbare, träge Welt physischer Server ausgelegt. In einer dynamischen OpenShift-Umgebung sind Pods dagegen kurzlebig. Sie bewegen sich. Sie skalieren. Sie fallen aus und starten auf anderen Knoten neu.
Wenn Ihre OpenShift-Speicherschicht nicht Kubernetes-nativ ist, sehen Sie sich mit drei entscheidenden Problemen konfrontiert:
- Latenz beim Einbinden: Das Warten darauf, dass ein älteres SAN bei der Migration eines Pods eine LUN einem neuen Knoten neu zuordnet, kann Minuten dauern. In einer Microservices-Architektur ist das eine Ewigkeit.
- Leistungsschwankungen: Herkömmlichen Arrays fehlt oft die detaillierte Transparenz, um bestimmte Persistent Volume Claims (PVCs) zu priorisieren. Das kann zu „Noisy-Neighbor“-Problemen führen, die die Anwendungsleistung beeinträchtigen.
- Komplexe Day-2-Operationen: Die Verwaltung des Speichers über eine separate Konsole außerhalb der OpenShift-oc-CLI oder der GitOps-Workflows unterbricht die Automatisierungskette.
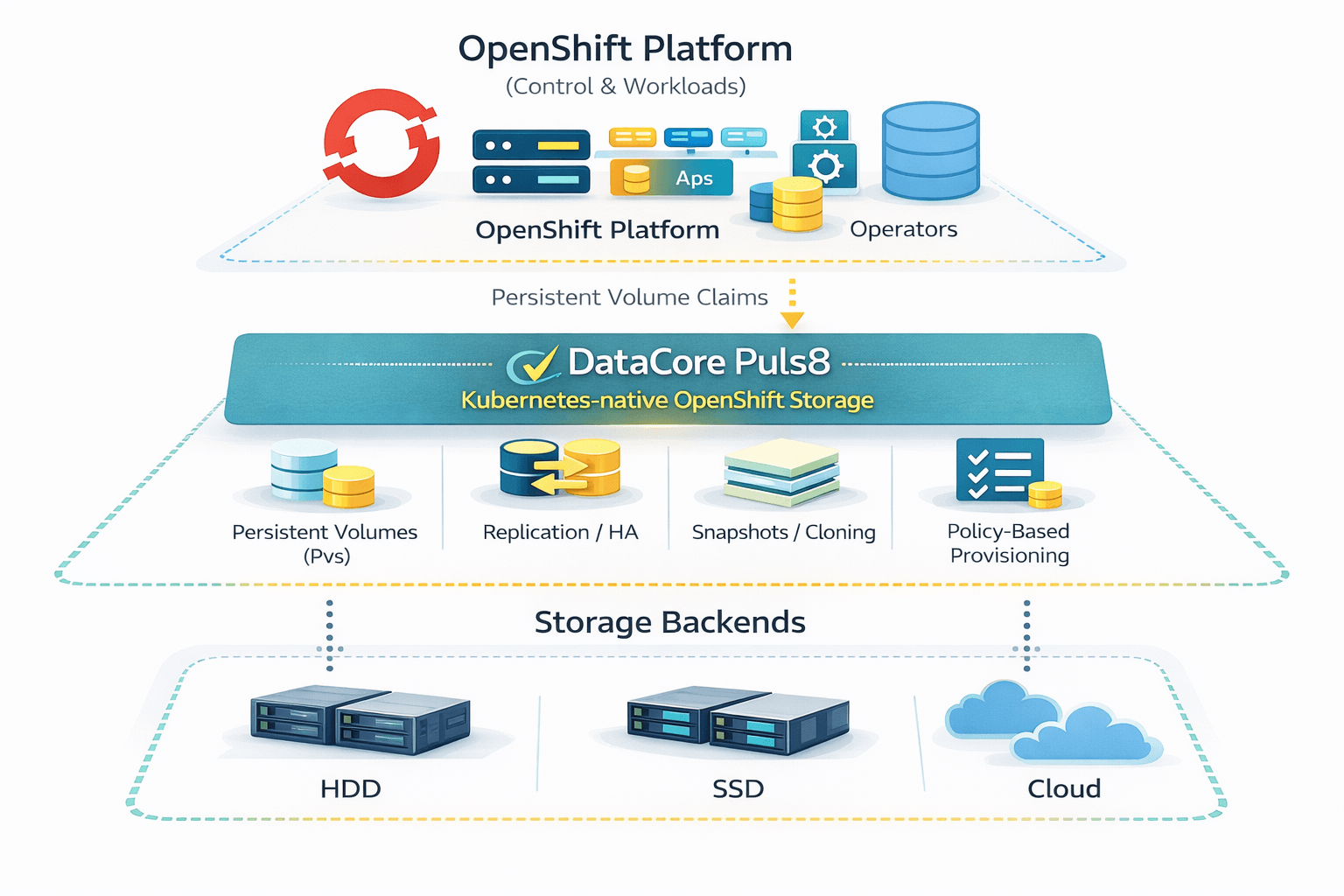
Die Lösung: DataCore Puls8 als OpenShift Storage Fabric
![]() DataCore Puls8 wurde entwickelt, um Reibungsverluste zwischen Orchestrator und Speicher zu beseitigen. Anstatt als externes Zusatzmodul zu fungieren, arbeitet Puls8 als verteilte Storage Fabric, die direkt im OpenShift-Cluster integriert ist. Dabei wird Speicher als vollwertiger Bestandteil des Kubernetes-Stacks behandelt.
DataCore Puls8 wurde entwickelt, um Reibungsverluste zwischen Orchestrator und Speicher zu beseitigen. Anstatt als externes Zusatzmodul zu fungieren, arbeitet Puls8 als verteilte Storage Fabric, die direkt im OpenShift-Cluster integriert ist. Dabei wird Speicher als vollwertiger Bestandteil des Kubernetes-Stacks behandelt.
Puls8 schließt diese „Lücke“, indem es die Datenebene in den Kernel-Bereich der Worker-Knoten verlagert. Dadurch wird sichergestellt, dass die Speicherleistung deterministisch ist. Wenn Sie ein Volume über eine StorageClass bereitstellen, reserviert Puls8 nicht nur Speicherplatz auf einem Array, sondern orchestriert auch einen Hochleistungspfad unter Verwendung von NVMe-over-Fabrics-(NVMe-oF)-Protokollen. So wird sichergestellt, dass die I/O-Latenz unabhängig von der Clustergröße im Sub-Millisekundenbereich bleibt.
Durch den Einsatz synchroner Replikation stellt Puls8 außerdem sicher, dass Daten über mehrere Verfügbarkeitszonen oder Knoten hinweg stets verfügbar sind. Dabei geht es nicht nur um ein „Backup“, sondern um ausfallsichere Kontinuität. Fällt ein Knoten aus, sind die Daten bereits auf einem anderen Knoten vorhanden. Somit kann der OpenShift-Scheduler den Pod sofort neu starten, ohne auf komplexe Speicher-Neuverknüpfungen warten zu müssen.
Der Leitfaden: Praktische Ausfallsicherheit in einem OpenShift-Cluster
Stellen Sie sich das folgende gängige Szenario vor: Sie betreiben einen geschäftskritischen MongoDB-Cluster auf OpenShift in einer Konfiguration mit drei Knoten.
In einer herkömmlichen Konfiguration verschiebt der OpenShift-Scheduler den MongoDB-Pod auf Knoten 2, wenn Knoten 1 ausfällt. Der CSI-Treiber muss dem externen Array dann signalisieren, das Volume von Knoten 1 zu entkoppeln und Knoten 2 zuzuordnen. Wenn der Befehl „unmap” hängt – was in älteren Fabric-Umgebungen häufig vorkommt –, wird das Volume gesperrt und Ihre Datenbank bleibt offline.
Mit DataCore Puls8 ist der Arbeitsablauf automatisiert und deterministisch:
- Bereitstellung: Sie definieren eine Puls8-StorageClass mit einem Replikationsfaktor von drei. Puls8 verteilt die Datenreplikate automatisch auf Ihre Worker-Knoten.
- Der Ausfall: Knoten 1 fällt unerwartet aus.
- Die Wiederherstellung: OpenShift erkennt den Ausfall und plant den Pod auf Knoten 2 ein. Da Puls8 bereits eine synchrone, bitgenaue Replik der Daten auf Knoten 2 gepflegt hat, ist das Volume sofort verfügbar.
- Das Ergebnis: Es ist kein manueller Eingriff erforderlich, es gibt keine „Stale Lock“ auf dem SAN und die Ausfallzeiten sind nicht länger. Die Anwendung nimmt den Betrieb innerhalb von Sekunden wieder auf.
Dieser Ansatz verwandelt die Speicherung von einer reaktiven Komponente in eine automatisierte Dienstleistung. Anstatt LUNs oder Masking zu verwalten, verwalten Sie Richtlinien über dieselben YAML-Manifeste, die Sie auch für Ihre Anwendungen verwenden.
Fazit: Technik für Sicherheit
Der Umstieg auf OpenShift ist eine strategische Entscheidung für eine moderne, automatisierte Infrastruktur. Diese Strategie ist jedoch nur so robust wie ihr schwächstes Glied. Wenn Sie eine Containerplattform der nächsten Generation mit veralteten Speicherarchitekturen betreiben, bringt das unnötige Risiken und betrieblichen Aufwand mit sich.
![]() DataCore Puls8 schlägt eine Brücke zwischen der Agilität von Kubernetes und der Zuverlässigkeit, die Unternehmen benötigen. Es geht nicht nur darum, Ihren Containern „Kapazität” zur Verfügung zu stellen, sondern eine ausfallsichere, leistungsstarke Datenebene bereitzustellen, die sich linear an Ihre Ambitionen anpasst. Es geht darum, zu wissen, dass Ihre Daten sicher sind und Ihre Leistung garantiert ist, statt nur darauf zu hoffen.
DataCore Puls8 schlägt eine Brücke zwischen der Agilität von Kubernetes und der Zuverlässigkeit, die Unternehmen benötigen. Es geht nicht nur darum, Ihren Containern „Kapazität” zur Verfügung zu stellen, sondern eine ausfallsichere, leistungsstarke Datenebene bereitzustellen, die sich linear an Ihre Ambitionen anpasst. Es geht darum, zu wissen, dass Ihre Daten sicher sind und Ihre Leistung garantiert ist, statt nur darauf zu hoffen.
Sind Sie bereit, Puls8 in Aktion zu erleben?

In diesem Video sehen Sie, wie DataCore Puls8 synchrone Replikation und automatisches Failover innerhalb eines Kubernetes-Clusters bereitstellt. So bleiben Ihre Daten auch bei Knotenausfällen zugänglich.
Um die Speicherherausforderungen von OpenShift zu lösen, ist ein Kubernetes-nativer Ansatz erforderlich, der konsistente Leistung, hohe Verfügbarkeit und vereinfachte Abläufe bietet.
