Cloud-native storage is a category of software-defined storage technology built specifically to run inside Kubernetes and other container-orchestration platforms. Unlike traditional storage systems that are adapted or bolted on to cloud-native environments after the fact, cloud-native storage treats containers and Kubernetes primitives, such as Persistent Volume Claims, Storage Classes, and Custom Resource Definitions, as first-class citizens in its architecture.
The defining characteristic of cloud-native storage is that its control plane, data plane, and lifecycle management are all orchestrated by Kubernetes itself. Storage controllers run as pods, volumes are provisioned declaratively through standard Kubernetes APIs, and scaling, failover, and upgrades follow the same patterns teams already use for stateless applications.
Why Cloud-Native Storage Exists
Modern applications are increasingly stateful. Organizations now run databases (PostgreSQL, MySQL, MongoDB), message queues (Kafka, RabbitMQ), analytics pipelines, AI/ML training workloads, and observability stacks (Elasticsearch, Prometheus) on Kubernetes. These workloads require persistent, high-performance, and resilient storage, but containers are ephemeral by design. They restart, reschedule across nodes, scale up and down, and fail unpredictably.
Traditional storage architectures (SAN appliances, NAS filers, and even earlier generations of software-defined storage) were not designed for this level of dynamism. They require manual provisioning, lack awareness of container lifecycles, and introduce operational complexity that slows down DevOps and platform engineering teams.
Cloud-native storage solves this mismatch by embedding storage intelligence directly into the Kubernetes orchestration layer, so persistent data follows the application wherever it moves across the cluster.
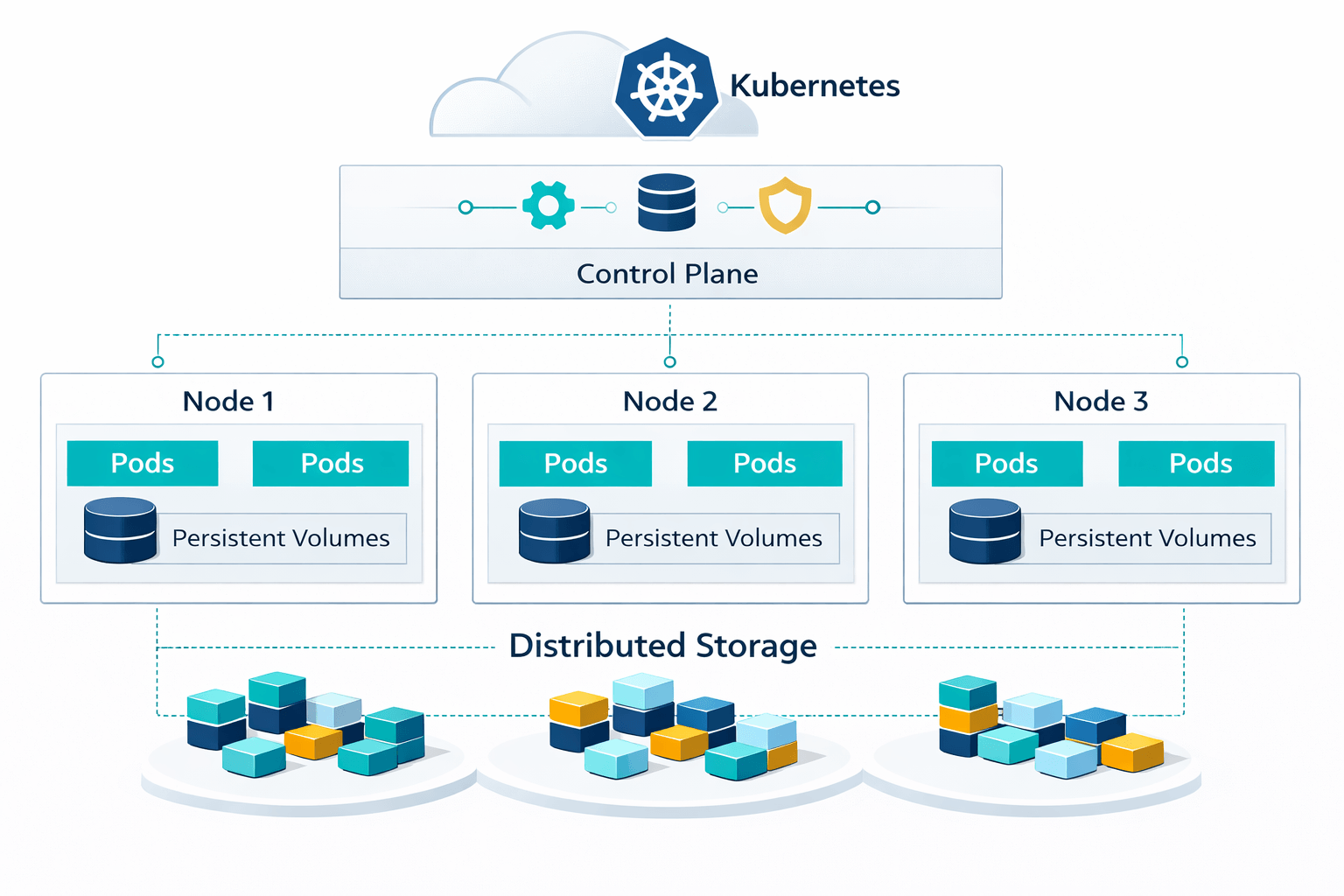
Core Capabilities of Cloud-Native Storage
Cloud-native storage platforms are evaluated across several key capability dimensions that distinguish them from legacy and adapted storage approaches.
 Dynamic Volume Provisioning: Storage volumes are created on-demand when an application requests them through a Persistent Volume Claim, without any manual intervention from an administrator. Kubernetes Storage Classes define the performance, replication, and availability characteristics of each volume type.
Dynamic Volume Provisioning: Storage volumes are created on-demand when an application requests them through a Persistent Volume Claim, without any manual intervention from an administrator. Kubernetes Storage Classes define the performance, replication, and availability characteristics of each volume type.
 Data Replication and High Availability: Cloud-native storage replicates data across nodes, racks, or availability zones to protect stateful workloads from hardware failures and node outages. This replication happens at the storage layer, transparent to the application, and ensures that pod restarts or rescheduling events do not result in data loss.
Data Replication and High Availability: Cloud-native storage replicates data across nodes, racks, or availability zones to protect stateful workloads from hardware failures and node outages. This replication happens at the storage layer, transparent to the application, and ensures that pod restarts or rescheduling events do not result in data loss.
 NVMe-Class Performance: Modern cloud-native storage platforms leverage local NVMe drives on Kubernetes worker nodes to deliver the low-latency, high-IOPS performance that demanding stateful workloads (databases, real-time analytics, AI inference) require. This approach eliminates the network bottlenecks and VM-level caps that throttle performance in traditional cloud disk architectures.
NVMe-Class Performance: Modern cloud-native storage platforms leverage local NVMe drives on Kubernetes worker nodes to deliver the low-latency, high-IOPS performance that demanding stateful workloads (databases, real-time analytics, AI inference) require. This approach eliminates the network bottlenecks and VM-level caps that throttle performance in traditional cloud disk architectures.
 Declarative, GitOps-Compatible Management: Storage configuration is defined in YAML manifests alongside application configuration, enabling infrastructure-as-code workflows, version control, and CI/CD integration. Platform teams manage storage the same way they manage every other Kubernetes resource.
Declarative, GitOps-Compatible Management: Storage configuration is defined in YAML manifests alongside application configuration, enabling infrastructure-as-code workflows, version control, and CI/CD integration. Platform teams manage storage the same way they manage every other Kubernetes resource.
 Observability and Monitoring Integration: Cloud-native storage integrates natively with Kubernetes monitoring ecosystems — Prometheus for metrics, Grafana for dashboards, Fluentd for log aggregation — giving teams unified visibility into storage health, performance, and capacity alongside application telemetry.
Observability and Monitoring Integration: Cloud-native storage integrates natively with Kubernetes monitoring ecosystems — Prometheus for metrics, Grafana for dashboards, Fluentd for log aggregation — giving teams unified visibility into storage health, performance, and capacity alongside application telemetry.
 Multi-Cluster and Hybrid-Cloud Portability: Because cloud-native storage abstracts the underlying infrastructure, applications and their persistent data can move between on-premises clusters, public cloud environments, and edge locations without reconfiguring storage backends or changing application code.
Multi-Cluster and Hybrid-Cloud Portability: Because cloud-native storage abstracts the underlying infrastructure, applications and their persistent data can move between on-premises clusters, public cloud environments, and edge locations without reconfiguring storage backends or changing application code.
Cloud-Native Storage vs. Traditional Storage vs. Cloud Provider Storage: How They Compare
Understanding the differences between storage approaches helps platform teams choose the right strategy for their Kubernetes environments.
Traditional SAN/NAS Storage
Traditional storage systems (SAN arrays, NAS filers) offer mature data services and high reliability, but they operate outside the Kubernetes ecosystem. Integration typically requires CSI drivers that bridge two fundamentally different management paradigms. Provisioning is often manual or semi-automated, scaling requires hardware procurement cycles, and operational teams need specialized storage expertise separate from their Kubernetes skills. For organizations running a mix of legacy and containerized workloads, traditional storage may still serve a role, but it introduces friction and operational overhead in pure Kubernetes environments.
Cloud Provider Managed Disks (EBS, Azure Disk, Persistent Disk)
Cloud-managed disks offer convenience and deep integration with their respective cloud platforms, but they come with notable trade-offs for Kubernetes workloads. Performance is often capped per-VM, latency is higher than local NVMe, and costs scale with IOPS provisioning, snapshot retention, and cross-zone data transfer. Portability is limited: storage configurations are cloud-specific, making multi-cloud strategies more complex. For development and testing environments or lightly stateful workloads, managed disks are often sufficient. For performance-sensitive production workloads, they frequently become a constraint.
Cloud-Native Storage
Cloud-native storage platforms are purpose-built for Kubernetes, running as containerized microservices within the cluster. They provision volumes dynamically through native Kubernetes APIs, replicate data across nodes for high availability, leverage local NVMe hardware for maximum performance, and integrate with the existing Kubernetes toolchain for monitoring, backup, and lifecycle management. This approach eliminates the operational gap between how teams manage applications and how they manage storage, enabling platform teams to standardize on a single operational model.
| Capability | Traditional SAN/NAS | Cloud Managed Disks | Cloud-Native Storage |
|---|---|---|---|
| Kubernetes-Native Provisioning | No, external management | Partial, cloud-specific APIs | Yes, PVCs and Storage Classes |
| Local NVMe Performance | Depends on fabric | No, network-attached | Yes, direct node storage |
| Multi-Cluster / Multi-Cloud | Manual, complex | Cloud-locked | Built-in portability |
| Declarative, GitOps-Ready | No | Limited | Yes |
| Integrated Observability | Separate tooling | Cloud-native monitoring | Prometheus, Grafana native |
| Scaling Model | Hardware-bound | Cloud capacity, pay-per-IOPS | Node-linear, predictable |
Key Use Cases for Cloud-Native Storage
- Stateful Databases on Kubernetes: Running PostgreSQL, MySQL, MongoDB, or Cassandra on Kubernetes requires persistent volumes with low latency, consistent IOPS, and automatic failover. Cloud-native storage provides the data replication and performance characteristics these databases demand without requiring them to run on dedicated infrastructure outside the cluster.
- AI/ML Training and Inference Pipelines: Machine learning workloads generate and consume large datasets that need high-throughput storage accessible across multiple pods. Cloud-native storage with ReadWriteMany support and NVMe performance enables distributed training jobs and real-time inference without I/O bottlenecks.
- CI/CD and Development Environments: Continuous integration pipelines require fast, ephemeral storage for build artifacts and test databases, while staging environments need persistent volumes that mirror production configurations. Dynamic provisioning through Kubernetes Storage Classes enables self-service storage for development teams.
- Observability and Search Stacks: Elasticsearch, the ELK stack, and Prometheus with long-term retention all require scalable, high-throughput persistent storage. Cloud-native storage scales linearly as new nodes are added to the cluster, ensuring observability infrastructure keeps pace with growing telemetry volume.
- Edge and Multi-Site Deployments: Organizations operating Kubernetes at the edge (retail locations, manufacturing plants, telecom infrastructure) need storage that works consistently across distributed sites with varying hardware profiles. Cloud-native storage abstracts these differences, providing a uniform storage experience from edge to core to cloud.
How to Evaluate a Cloud-Native Storage Platform
When selecting a cloud-native storage solution for production Kubernetes environments, platform teams should assess candidates across these critical dimensions:
- Kubernetes-Native Architecture: Is storage provisioned, managed, and monitored entirely through Kubernetes APIs and workflows, or does it require a separate management plane? True cloud-native storage should feel like a natural extension of Kubernetes, not an external system integrated through adapters.
- Performance Under Real Workloads: Benchmark with your actual applications — databases, message queues, analytics workloads — under realistic concurrency and failure scenarios. Measure IOPS, latency percentiles (p50, p95, p99), and throughput during normal operations and during node failure or recovery events.
- Data Protection and Resilience: Evaluate replication policies, snapshot capabilities, and integration with backup tools like Veeam Kasten or Velero. Understand recovery time and recovery point objectives for your most critical workloads.
- Operational Simplicity: Assess the learning curve for your team, the quality of documentation, upgrade procedures, and day-2 operational requirements. The total cost of ownership includes your team’s time spent managing storage.
- Licensing and Cost Predictability: Understand the licensing model: per-node, per-TB, per-cluster, or usage-based. Factor in hidden costs such as data transfer fees, snapshot storage, and disaster recovery overhead. Predictable, node-based licensing avoids surprise costs as data volumes grow.
- Ecosystem Compatibility: Confirm integration with your Kubernetes distribution (OpenShift, Rancher, Tanzu, upstream Kubernetes), monitoring tools (Prometheus, Grafana), backup solutions, and service mesh or GitOps toolchains.
Frequently Asked Questions About Cloud-Native Storage
Software-defined storage (SDS) is the broader category — any storage architecture where management and provisioning are abstracted from hardware and controlled through software. Cloud-native storage is a specific subset of SDS designed to run inside Kubernetes, using Kubernetes-native APIs, lifecycle management, and orchestration patterns. All cloud-native storage is software-defined, but not all software-defined storage is cloud-native.
These are all Kubernetes storage solutions, but they differ significantly in architecture, performance, and operational complexity. Portworx is a commercial platform with a broad feature set but complex licensing. Longhorn, a CNCF incubating project, is lightweight but may lack the performance and enterprise data services needed for production-scale stateful workloads. Rook-Ceph brings the power of Ceph to Kubernetes but introduces significant operational complexity. When evaluating, focus on NVMe performance under real workloads, ease of day-2 operations, replication and failover behavior, and total cost of ownership across your cluster footprint.
For Kubernetes-hosted workloads, yes — cloud-native storage provides the persistence, performance, and resilience these workloads need without requiring external storage infrastructure. For workloads that remain on traditional VMs or bare-metal servers outside Kubernetes, your existing SAN or NAS may still be the right fit. Many organizations run both in parallel during migration.
Yes. Because cloud-native storage abstracts the underlying infrastructure and uses standard Kubernetes APIs, it provides a consistent storage experience across on-premises, AWS, Azure, GCP, and edge environments. This is a significant advantage over cloud-provider managed disks, which lock storage configuration to a specific cloud.
Cloud-native storage that leverages local NVMe drives on Kubernetes nodes typically delivers dramatically higher performance than network-attached cloud managed disks. For example, benchmarks have shown up to 14× more read IOPS and 3× higher throughput compared to standard cloud persistent disk offerings, while also reducing storage costs.
Mature cloud-native storage platforms are deployed in production across industries for mission-critical stateful workloads including financial transaction databases, AI-driven document processing, electronic signature management, and multi-site Kubernetes-as-a-Service offerings. The key is selecting a platform with proven enterprise data services — replication, snapshots, backup integration, and 24/7 support.
Cloud-Native Storage From DataCore: Puls8
DataCore Puls8 is a Kubernetes-native persistent storage platform purpose-built for stateful workloads in production environments. Developed around the CNCF open-source project OpenEBS, Puls8 delivers NVMe-class performance, synchronous data replication across nodes and availability zones, and a fully declarative management model that integrates natively with Kubernetes APIs.
Puls8 is designed for platform engineering, DevOps, and SRE teams that need enterprise-grade storage without leaving the Kubernetes operational model. Key capabilities include dynamic volume provisioning via PVCs and Storage Classes, support for both local and replicated volumes, a centralized control plane for multi-cluster environments, and native integration with Prometheus, Grafana, Veeam Kasten, and Velero.
Named the 2026 Kubernetes Storage Award winner by StorageNewsletter, Puls8 is deployed in production across multi-cluster environments powering databases, AI/ML workloads, observability stacks, and CI/CD pipelines. It runs on any standard Kubernetes environment: on-premises, in the cloud, or at the edge — and is licensed per node with no hidden capacity, IOPS, or volume limits.
