Most data centers have different classes of storage media such as SATA disks, SAS disks and SSDs/Flash. Each class can have many different subcategories, especially SSDs/Flash, and they all differ in terms of access speed, capacity, and price. You want your most frequently accessed data to stay on the fastest storage media, but the fastest media is also the rarest because it is expensive.
自動階層化とは
自動階層化により、事前定義されたルールまたはポリシーに基づいて最適な状態でデータをストレージメディアに保存し、その後読み取ることができます。階層型ストレージのデータクラスへのこのアプローチは、アプリケーションが最もアクセスしているデータセット(ホットデータ)を自動的に検出し、最も速いストレージに配置します。ウォームデータ、コールドデータも同様で、データは自動的に第2層以下のストレージに配置されます。これらはすべてリアルタイムで動的に行われ、しかもバックグラウンドでは見えません。データの使用量に応じて、自動的にランクアップやランクダウンが行われるため、ミッションクリティカルな情報やビジネスクリティカルな情報にも最適な速度で対応することができます。組織全体のアプリケーション速度を最大化し、ストレージインフラストラクチャをビジネスニーズに合わせてカスタマイズする方法については、以下の機能をご覧ください。
Tiering vs Caching: What’s the Difference
At first glance, tiering and caching solutions may look similar but there are fundamental differences in the utilization of faster storage and the underlying technology leveraged to identify and speed up your most frequently accessed data.

High-Speed Caching is a proprietary caching algorithm that accelerates I/O by leveraging RAM as a read and write cache. DataCore supports up to 8 TBs of high-speed cache per node, creating a true “mega-cache” to turbocharge application performance.
RAM is a commodity component and therefore relatively inexpensive, yet it possesses outstanding performance characteristics and lacks the shortcomings that are attributed to Flash devices. RAM is an excellent technology to leverage for accelerating I/O performance and delivers a very high benefit-to-cost ratio across the entire storage architecture.
High-Speed Caching is critical for maintaining application performance because RAM is many orders of magnitude faster than the fastest Flash technologies and it resides as close to the CPU as possible. It is the fastest storage component in the architecture, delivering a 3-5x performance boost to applications and freeing up application servers to perform other tasks. It also extends the life of traditional storage components by minimizing the stress experienced from disk thrashing.
Application workloads are hard to predict. Auto-Tiering is a real-time intelligent mechanism that continuously positions data on the appropriate class of storage based on how frequently the data is accessed. The result is superior application performance and lower TCO across the entire storage architecture.
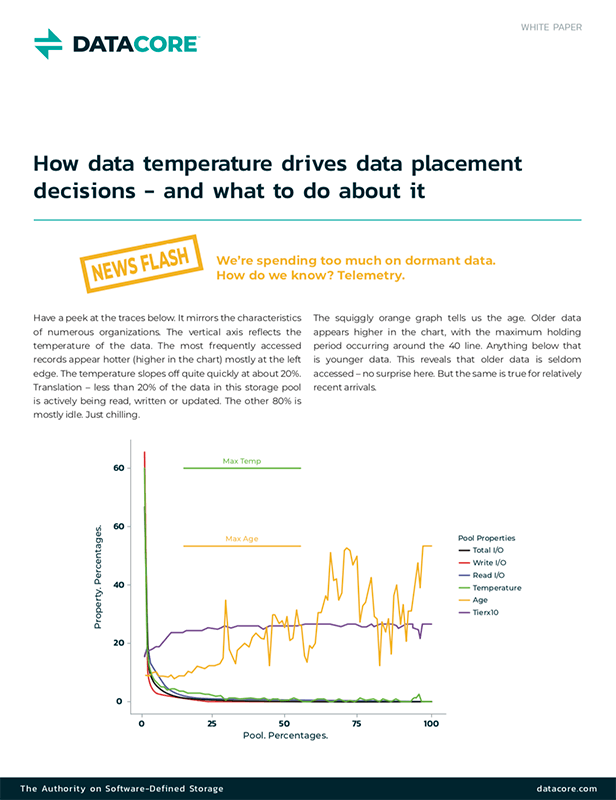
Tiered storage avoids the need to invest heavily in expensive Flash technology. Industry statistics show that, on average, only 15-20% of a company’s entire data footprint benefits from Flash storage since the remaining percentage is considered largely dormant.
According to Gartner, “The access patterns, value and usage characteristics of data stored within storage arrays varies widely, and is dependent on business cycles and organizational work processes. Because of this large variability, data stored within storage devices cannot be economically and efficiently stored on the same storage type, tier, format or media.”

Auto-Tiering leverages any combination of Flash and traditional disk technologies, whether it is internal or array based, with support up to 15 different storage tiers. For example:
| Tier | Details | % OF TOTAL PRODUCTION |
| 1 | Ultra-High-Speed Disk (Flash) | 15% |
| 2 | High Speed Disk (SAS 15k) | 25% |
| 3 | Capacity Disk (SAS 7.2k NL) | 60% |
| 4 | Test/Dev Disk (SATA) | As Needed |
| 5 | Archival Cloud Disk | As Needed |
As more advanced disk technologies become available, existing storage tiers can be modified as necessary and additional ones can be added to further diversify the tiered storage architecture.
自動階層化の主な利点
- 動的データ分析:データアクセスパターンのリアルタイム監視で最適な階層配置を実現
- シームレスな移行: ストレージ階層間で無停止かつ自動化された移動を実現
- クロスデバイスでの一貫性:さまざまなベンダーのデバイス間で均一な自動階層化を実現
- 効率的なスペース利用:最適なデータ配置でストレージ容量を最大化
- 完全自動化:一度設定すればその後のすべてが自動化され、手動介入が不要に
適応型データ配置:自動階層化の利点を拡張
その後、SANsymphonyはデータアクセスのパターンを動的に追跡し、自動階層化を採用してデータセットが常に最適なストレージ階層に配置されるようにすることで、パフォーマンスと容量の両方をリアルタイムで最適化します。
その結果、以下を実現できます。
- ホットデータで可能な限り最高のパフォーマンス
- コールドデータのフットプリントを可能な限り最小化
