
When a traditional external storage array isn’t enough, it’s usually because the infrastructure has evolved faster than the data plane. For years, the industry operated under the assumption that storage was a static entity—a “black box” sitting outside the compute cluster. But as Red Hat OpenShift becomes the cornerstone of the modern data center, that separation is no longer just an architectural nuance; it is a performance bottleneck.
Since the beginning of 2024, the momentum behind Red Hat OpenShift has accelerated to unprecedented levels. According to recent data from Red Hat, customer adoption of OpenShift Virtualization alone has surged by 178% since early 2024, with production deployments growing significantly as organizations seek a stable, scalable alternative to legacy hypervisors. This shift is driven by a need for a unified substrate that handles both containerized microservices and legacy virtual machines. However, as you scale these environments, you quickly discover that while OpenShift can orchestrate a thousand containers in seconds, the underlying OpenShift storage often struggles to keep pace.
OpenShift Storage Challenge: The “Stateful” Friction in a Stateless World
The industry often tells you that the Container Storage Interface (CSI) is the universal answer to Kubernetes storage. In practice, the CSI is merely a translator. It allows OpenShift to “talk” to an external array, but it does nothing to address the fundamental architectural mismatch between distributed orchestration and centralized storage.
The hidden problem isn’t just connectivity; it’s latency and deterministic behavior.
When you run high-performance stateful workloads—such as PostgreSQL, Kafka, or AI training pipelines—on OpenShift, you encounter the “I/O Blender” effect. Traditional SANs are designed for the predictable, slow-moving world of physical servers. In a dynamic OpenShift environment, pods are ephemeral. They move. They scale. They fail and restart on different nodes.
If your OpenShift storage layer isn’t Kubernetes-native, you face three critical gaps:
- Mount-Time Latency: Waiting for a legacy SAN to re-map a LUN to a new node when a pod migrates can take minutes. In a microservices architecture, minutes are an eternity.
- Performance Inconsistency: Traditional arrays often lack the granular visibility to prioritize specific Persistent Volume Claims (PVCs), leading to “noisy neighbor” issues that degrade application performance.
- Complex Day 2 Operations: Managing storage through a separate console, outside of OpenShift’s oc CLI or GitOps workflows, breaks the automation chain.
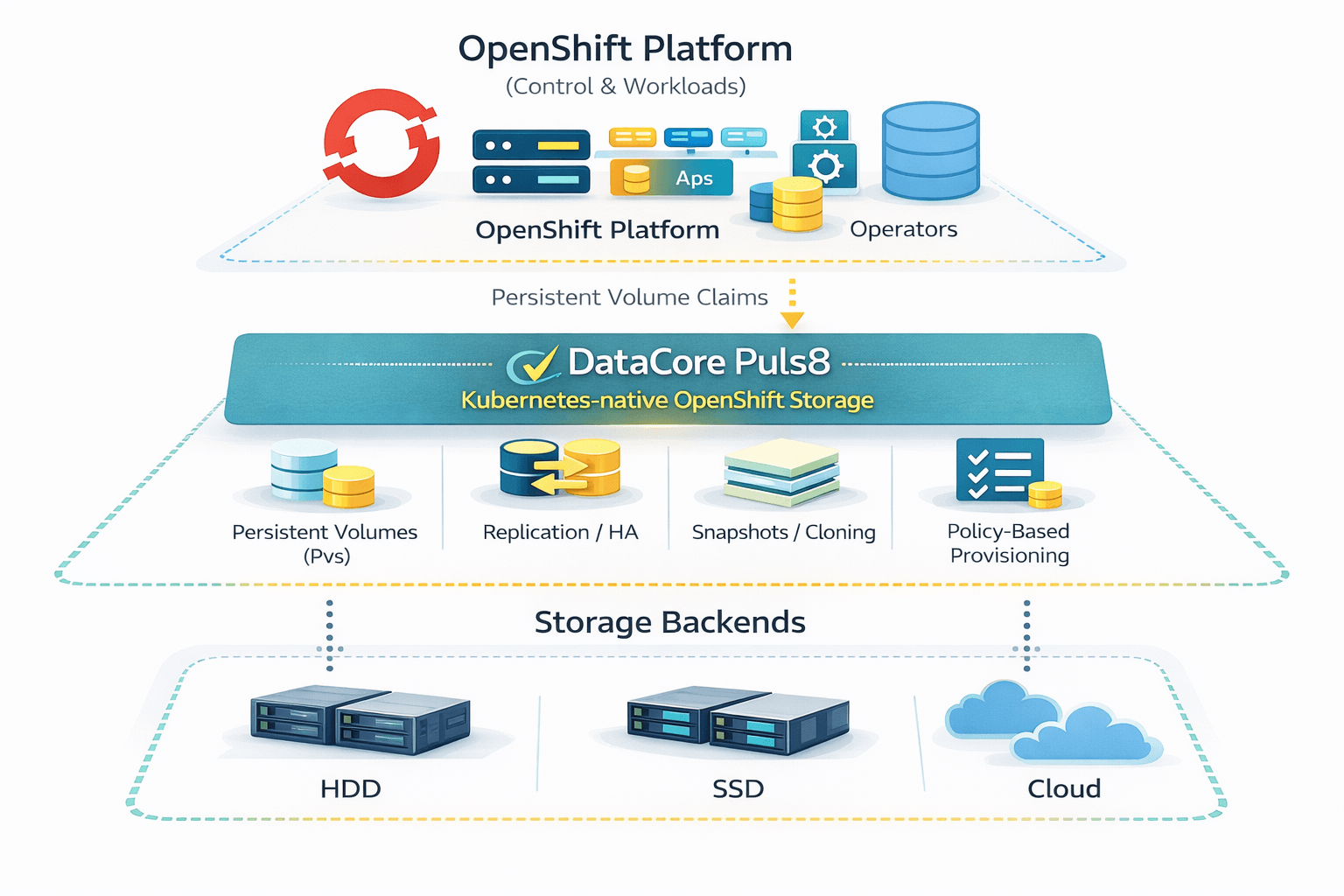
The Solution: DataCore Puls8 as OpenShift Storage Fabric
![]() DataCore Puls8 is engineered to eliminate the friction between the orchestrator and the disk. Rather than acting as an external attachment, Puls8 functions as a distributed storage fabric that lives within the OpenShift cluster. It treats storage as a first-class citizen of the Kubernetes stack.
DataCore Puls8 is engineered to eliminate the friction between the orchestrator and the disk. Rather than acting as an external attachment, Puls8 functions as a distributed storage fabric that lives within the OpenShift cluster. It treats storage as a first-class citizen of the Kubernetes stack.
Puls8 resolves the “gap” by moving the data plane into the kernel space of the worker nodes. This ensures that storage performance is deterministic. When you provision a volume via a StorageClass, Puls8 doesn’t just carve out space on an array; it orchestrates a high-performance path using NVMe-over-Fabrics (NVMe-oF) protocols to ensure that I/O latency remains at sub-millisecond levels, regardless of cluster scale.
By using synchronous replication, Puls8 ensures that data is always available across multiple availability zones or nodes. This isn’t just about “backup”; it’s about resilient continuity. If a node fails, the data already exists on another node, allowing the OpenShift scheduler to restart the pod instantly without waiting for complex storage re-attachments.
The Walkthrough: Real-World Resilience in an OpenShift Cluster
Consider a common scenario: You are running a mission-critical MongoDB cluster on OpenShift across a three-node configuration.
In a traditional setup, if Node 1 fails, the OpenShift scheduler moves the MongoDB pod to Node 2. The CSI driver must then signal the external array to unmap the volume from Node 1 and map it to Node 2. If the “unmap” command hangs—a common occurrence in legacy fabrics—the volume becomes locked, and your database remains offline.
With DataCore Puls8, the workflow is automated and deterministic:
- Provisioning: You define a Puls8 StorageClass with a replication factor of three. Puls8 automatically distributes data replicas across your worker nodes.
- The Failure: Node 1 goes offline unexpectedly.
- The Recovery: OpenShift detects the failure and schedules the pod on Node 2. Because Puls8 has already maintained a synchronous, bit-for-bit replica of the data on Node 2, the volume is instantly available.
- The Business Outcome: There is no manual intervention, no “stale lock” on the SAN, and no extended downtime. The application resumes operation in seconds.
This approach transforms storage from a reactive component into an automated utility. You are no longer managing LUNs or masking; you are managing policies through the same YAML manifests you use for your applications.
Conclusion: Engineering for Certainty
The move to OpenShift is a strategic decision to embrace modern, automated infrastructure. However, that strategy is only as robust as its weakest link. Relying on legacy storage architectures to power a next-generation container platform introduces unnecessary risk and operational overhead.
![]() DataCore Puls8 provides the bridge between the agility of Kubernetes and the reliability required by the enterprise. It’s not about merely providing “capacity” to your containers; it’s about providing a resilient, high-performance data plane that scales linearly with your ambitions. It’s about knowing your data is safe and your performance is guaranteed, not just hoping it is.
DataCore Puls8 provides the bridge between the agility of Kubernetes and the reliability required by the enterprise. It’s not about merely providing “capacity” to your containers; it’s about providing a resilient, high-performance data plane that scales linearly with your ambitions. It’s about knowing your data is safe and your performance is guaranteed, not just hoping it is.
Ready to see Puls8 in action?

This video demonstrates how DataCore Puls8 provides synchronous replication and automatic failover within a Kubernetes cluster to ensure data remains accessible even during node failures.
Solving OpenShift storage challenges requires a Kubernetes-native approach that delivers consistent performance, high availability, and simplified operations.
