
When Kubernetes “Self-Healing” Isn’t Enough
Kubernetes is often celebrated for being a self-healing platform. Pods restart on their own, workloads reschedule automatically, and the cluster absorbs small failures without drama. But the moment you are running mission-critical applications that absolutely must stay online—customer-facing systems, transactional workloads, internal services that can’t go down—“self-healing” stops being a luxury and becomes a hard requirement. Suddenly, even a few minutes of downtime matter, and teams discover that real high availability in Kubernetes is not as automatic as it sounds.
The Hidden HA Gap: Pod Recovery vs. Data Availability for Stateful Applications
![]() High availability in Kubernetes works on two levels: the control plane and the applications themselves. A resilient control plane keeps the cluster functioning even when nodes fail, ensuring Kubernetes can make decisions and move workloads as needed. For applications, especially stateless ones, Kubernetes does a great job keeping replicas running and restarting them when something goes wrong. But this only covers half the story. Stateful applications (built with StatefulSets) in Kubernetes that rely on consistent, immediately accessible data don’t tend to recover as smoothly. Kubernetes can restart the pod, but it cannot guarantee that the StatefulSet’s data will be instantly available after a failure, often leaving the pod stuck in a pending or crash-loop state until its storage comes online.
High availability in Kubernetes works on two levels: the control plane and the applications themselves. A resilient control plane keeps the cluster functioning even when nodes fail, ensuring Kubernetes can make decisions and move workloads as needed. For applications, especially stateless ones, Kubernetes does a great job keeping replicas running and restarting them when something goes wrong. But this only covers half the story. Stateful applications (built with StatefulSets) in Kubernetes that rely on consistent, immediately accessible data don’t tend to recover as smoothly. Kubernetes can restart the pod, but it cannot guarantee that the StatefulSet’s data will be instantly available after a failure, often leaving the pod stuck in a pending or crash-loop state until its storage comes online.
Here’s where most teams hit the real HA challenge. If a node suddenly goes down, Kubernetes quickly brings the pod back on another node. That part works beautifully. The problem is what happens to the data the application was using when the failure occurred. The real problem is what happens to the data the application was using when the failure occurred. If that volume isn’t available on another node or if the data wasn’t already kept in a synchronized state, the restarted pod can’t actually recover. It simply waits, unable to run, because its state isn’t there. This gap between workload failover and data readiness is the piece many clusters struggle with. And it’s the reason organizations start looking for stronger ways to keep applications and their data available when Kubernetes nodes fail.
DataCore Puls8: Bringing True High Availability to Stateful Kubernetes Workloads
Closing the Gap Between Pod Recovery and Data Availability
To solve the gap between pod recovery and data availability, DataCore Puls8 provides a unified approach to high availability for stateful applications. Instead of relying on separate tools for storage and failover, Puls8 keeps each volume consistently up to date across multiple nodes. This ensures that when a pod restarts on another node, its persistent data is immediately available and the application can resume without interruption.
Synchronous Mirroring for Immediate State Availability
With Puls8, writes are committed in a coordinated fashion across multiple instances so the application’s data stays current and consistent where it’s needed. This prepares the cluster for disruption: when a node becomes unreachable, the real risk isn’t that Kubernetes won’t restart the pod—it’s whether the workload can start with the correct state. Puls8 avoids this risk by ensuring an up-to-date copy of the data is already available on another node before any failover occurs.

How the Architecture Ensures Deterministic Consistency
Technically, Puls8 uses a distributed, block-level mirrored volume architecture exposed through a CSI driver. Write acknowledgements are returned only when the participating instances have confirmed the update, ensuring deterministic consistency even during heavy or bursty activity. This prevents data drift or recovery delays that often occur with more loosely synchronized storage approaches in Kubernetes environments.
Instant Volume Availability and Automated Replica Management
When a node goes offline, Puls8 re-attaches an available synchronized instance of the volume immediately. Puls8 can also automatically restore the desired number of volume instances (replicas) after a failure and retire any outdated copies once the cluster stabilizes.
Failover That Ensures Continuity
Kubernetes reschedules the pod, mounts the fully synchronized replicated PV, and the application continues from the exact point where it left off—without rebuilds, resync cycles, data loss windows, or slow reattachment procedures. Failover is automatic, transparent, and fast enough that stateful services behave with the smoothness of stateless ones, but with full data integrity preserved.
How Puls8 Handles a Node Failure in Real Life
In this example, we see a WordPress application running on Node 1 under normal operating conditions. The pod is healthy and serving traffic as expected.
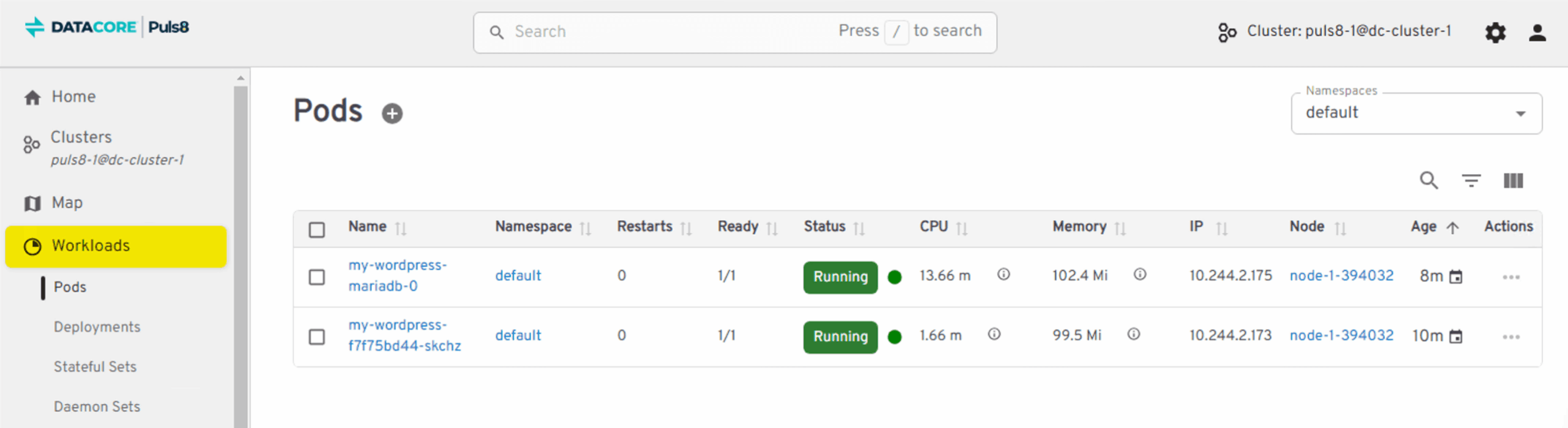
The cluster consists of three nodes (Node 0, Node 1, and Node 2), giving Kubernetes and Puls8 the environment needed to keep the stateful workload running reliably. Puls8 is continuously maintaining the application’s data across multiple synchronized instances in the background, so the latest state is always ready on another node.
In the below screen, we can see that replication is configured across all three nodes.
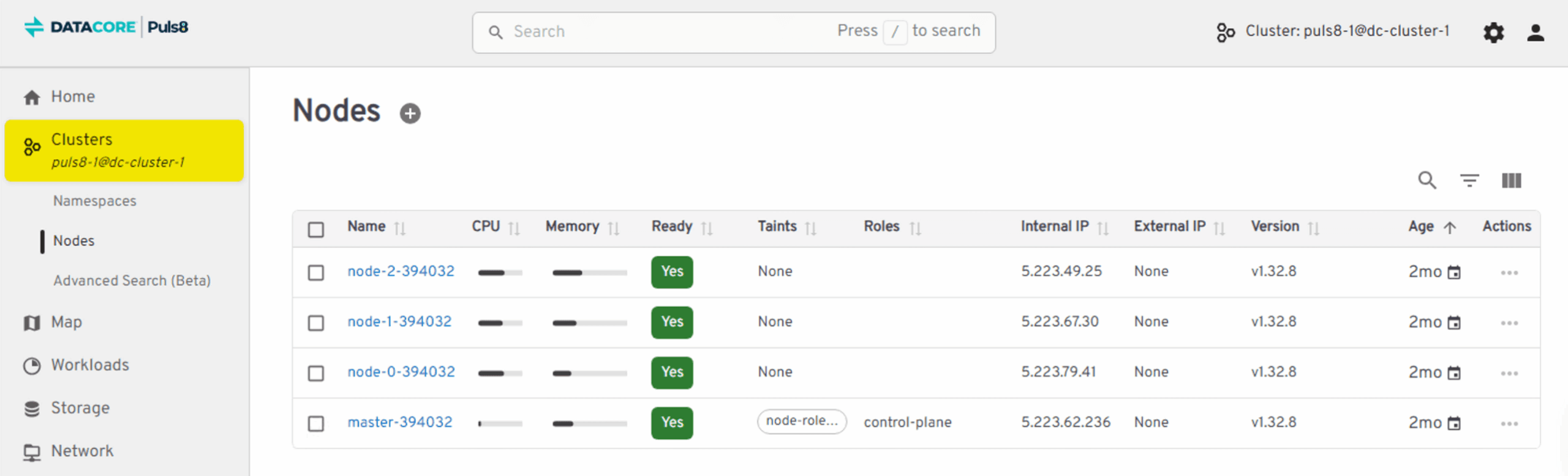
The next Puls8 screen shows all three nodes running in a healthy, synchronized data state.
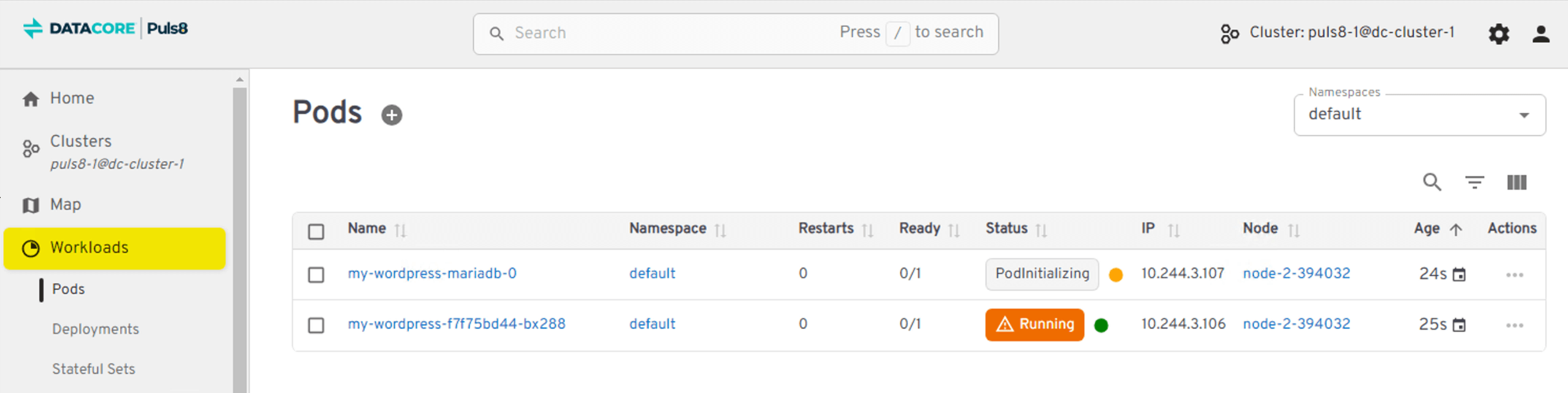
Now we see that Node 1 unexpectedly goes offline. This is the point where the workload on that node becomes unavailable, and Kubernetes must relocate the pod to keep the application running.
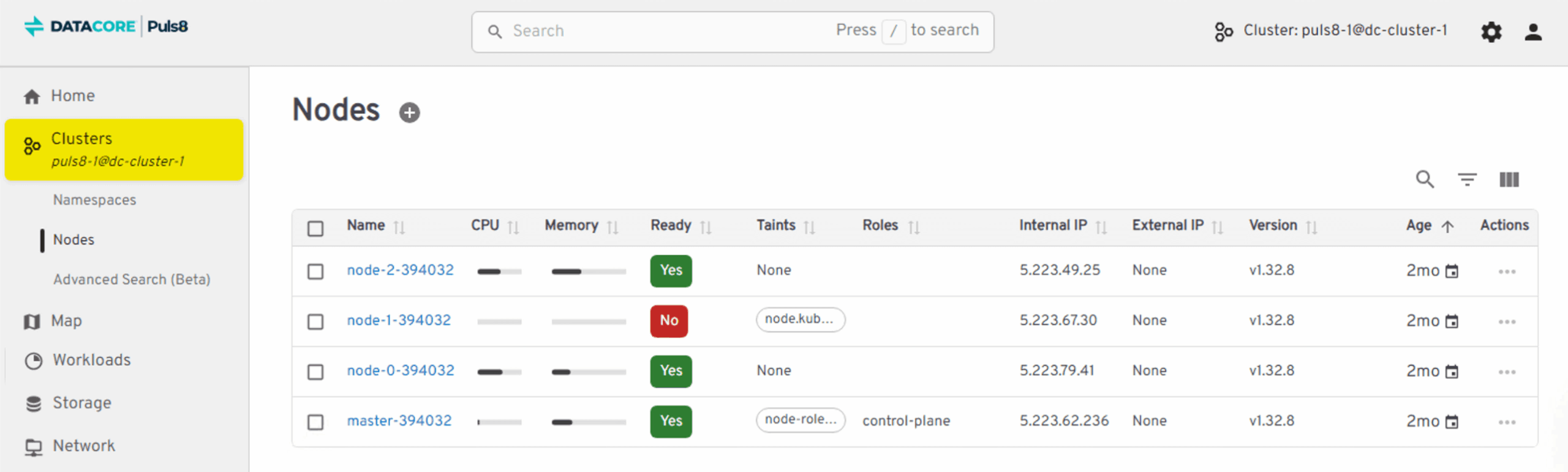
The WordPress application now fails over to Node 2. Because Puls8 had been replicating the data beforehand, the pod can restart immediately on the new node with the correct, current application state.
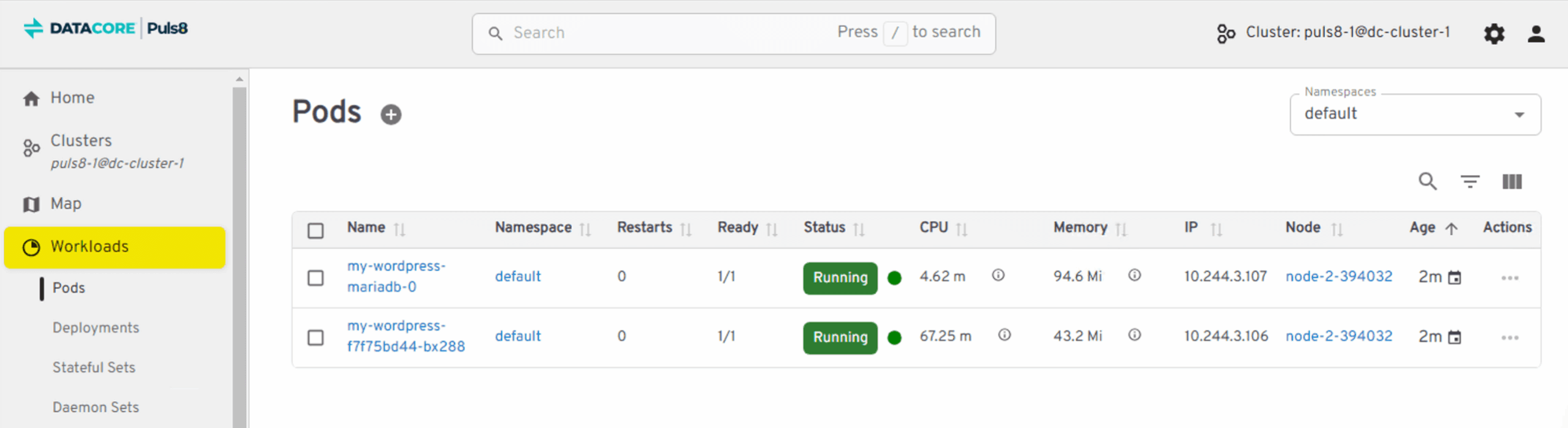
The application is now running normally on Node 2 in a healthy state. Thanks to Puls8’s continuous replication and seamless failover, the stateful workload continues operating without downtime or disruption.
Conclusion: Kubernetes High Availability, Done Right

High availability in Kubernetes is ultimately about confidence that workloads stay online, that data remains intact, and that disruptions don’t translate into downtime. By pairing synchronized data replication with automated application failover, DataCore Puls8 gives stateful workloads the same level of resilience and predictability that stateless services enjoy. It creates a foundation where continuity isn’t something you hope for during a failure; it’s something you can rely on.
This is why we call this capability “Lifeline”. In the moment a node disappears, Lifeline ensures the application doesn’t. It preserves state, maintains consistency, and keeps the service running without hesitation, acting as the safety net every mission-critical workload depends on. To experience how Puls8 brings true high availability to Kubernetes, request a trial from DataCore and see the difference firsthand.

