Ein englisches Sprichwort besagt, dass man kein Omelett machen kann, ohne Eier aufzuschlagen.
Eine interessante Redensart mit einer noch interessanteren (und düsteren!) Geschichte, die auf alle möglichen Lebenslagen passt und im Grunde darauf beruht, dass man kurzfristig etwas einsetzen muss, um langfristig etwas zu erreichen.
In gewisser Weise gilt das auch für die Virtualisierung. Wir simulieren andere Systeme durch Software. Das kostet möglicherweise etwas an Performance, doch keine Sorge: Es lohnt sich, denn die Vorteile überwiegen.
Bei der Server-Virtualisierung ist die Kosten-Nutzen-Rechnung einfacher nachzuvollziehen. Solche Umgebungen sind mittlerweile weit verbreitet. Wir sehen immer häufiger Multikern-Serverarchitekturen und erleben, dass die Managementabläufe effizienter und effektiver sind.
Bei der Speichervirtualisierung erschließt sich der Kostenvorteil nicht direkt auf den ersten Blick. Das beginnt mit der Sache, die virtualisiert wird. Es handelt sich entweder um ein (scheinbar) unintelligentes Gerät oder um ein teures, intelligentes Speichersystem. Warum sollte man so etwas (das Eine wie das Andere) virtualisieren?
Es gibt überzeugende Gründe für die Speichervirtualisierung, einschließlich solcher, die man nicht sofort sieht. Kann man sie erst sehen, liegen sie auf der Hand.
Warum ist Virtualisierung also vorteilhaft?
Nur, weil wir das behaupten?
Auf der Speichervirtualisierungsseite unserer Website finden Sie die typischen Formulierungen, mit denen Anbieter üblicherweise die Vorteile der Virtualisierung anpreisen:
- Geringere Kosten
- Höhere Zuverlässigkeit
- Verbesserte Performance
- Mehr Flexibilität und Skalierbarkeit
Das wirft möglicherweise Fragen auf. Welche Kosten sind das überhaupt? Welche Vorteile lassen sich wie erzielen?
Der Einsatz
Generell ist Virtualisierung eine zusätzliche Softwareebene, die man auf unterschiedliche Weise erreichen kann. Jon Toigo unterscheidet zwischen „in-band“ und „out-of-band“ Methoden, doch letztendlich handelt es sich immer um eine zusätzliche Ebene, die im Datenpfad berücksichtigt werden muss.
Wenn wir eine Speichervirtualisierungsebene einbauen, nehmen wir im Prinzip die Geräte, die lesen und schreiben, und packen sie in eine Software, die diese Lese- und Schreibvorgänge simuliert. Ein bisschen so wie auf der Stelle zu laufen. Aber warum?
Was bringt das?
Wir haben damit einen Platz im Datenpfad geschaffen, an dem ein leistungsstarker Allzweckcomputer eine Software ausführen kann. So entsteht enormes Mehrwertpotenzial, einschließlich der oben bereits genannten Punkte:
- Geringere Kosten
- Höhere Zuverlässigkeit
- Verbesserte Performance
- Mehr Flexibilität und Skalierbarkeit
Um zu sehen, wie diese Vorteile umgesetzt werden, schauen wir uns die Virtualisierung einmal genauer an.
Punkte für gutes Verhalten
Das Zusammenspiel zwischen den Anwendungen und dem Speicher kann man als Zugriffsmethode bezeichnen. Diese kann als Programmierschnittstelle, kurz API, modelliert werden. Die API definiert das erwartete Verhalten und liefert uns einen praktischen Rahmen für die Virtualisierung.
Der Blockspeicher ist eine Zugriffsmethode, die das SCSI Architecture Model (SAM) als „Execute Command remote procedure“ definiert:

Geringere Kosten
Zunächst können wir Blöcke voller Nullen mit … nichts darstellen! Null-Blöcke müssen nicht gespeichert werden – eine gängige Thin-Provisioning-Methode. Thin Provisioning vereinfacht die Kapazitätsplanung. Es verbessert die Nutzung der zugrunde liegenden Kapazität, um Kosten zu sparen. Spinnt man diesen Gedanken weiter, kommt man zur Deduplizierung, die doppelte Blockdaten in einzelne Instanzen im Speicherpool herunterbricht.
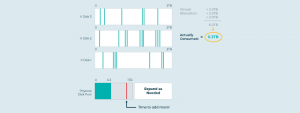
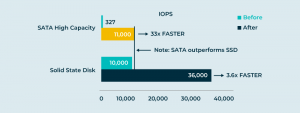
Wir können Zugriffsmuster bei virtuellen Blöcken verfolgen, die „Temperatur“ eines jeden Blocks synthetisieren und die Blöcke innerhalb eines Storage Pools so anordnen, dass „heiße“ Daten in schnellen (teuren) Speicher und „kalte“ Daten in langsamen (preiswerten) Speicher oder die Cloud befördert werden. Diese Auto-Tiering-Funktion arrangiert die Daten in virtuellen Disks, sodass die Anwendungen die Daten sehen, die sie benötigen, während das Virtualisierungssystem die Daten dynamisch und automatisch anhand der Kosten und Performance zuweist. Das senkt die Kosten weiter und verbessert dabei die Performance. Darauf gehen wir gleich noch näher ein.
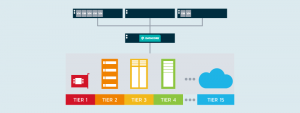
Höhere Zuverlässigkeit
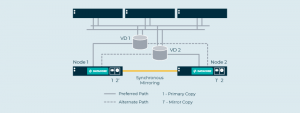
Datenblöcke können an zwei oder mehr Orten auf verschiedenen Hardwareplattformen gespeichert werden, um Hochverfügbarkeit zu gewährleisten und vor Ausfällen zu schützen.
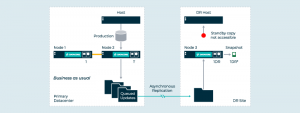
Datenblöcke können über das Internet verteilt werden, um für Notfälle gerüstet zu sein.
Mehr Flexibilität und Skalierbarkeit
Virtuelle Disks bleiben logisch konstant, während die Datenblöcke „im Hintergrund“ automatisch verschoben werden. Das vereinfacht Migrationen. Verbinden Sie ein neues Speichersystem einfach mit dem hinteren Ende der Speichervirtualisierungssoftware und übertragen Sie die Daten automatisch und nahtlos in den neuen Speicher.
Sie wollen horizontal skalieren? Fügen Sie einfach weitere Server für die Speichervirtualisierung hinzu, um eine N+1-Architektur zu erhalten. Die virtuellen Disks können Sie zwischen diesen Servern bewegen, nach einem ähnlichen Konzept wie bei einer Live-Migration virtueller Maschinen, um die Last neu zu verteilen.
Verbesserte Performance
Sollten sich durch die zusätzliche Verarbeitung und Komplexität nicht die Latenz erhöhen und der Durchsatz verringern? Nicht unbedingt – und das ist vermutlich noch interessanter als die ganzen Speicherdienste.
Wie ist das möglich? Das System kann dynamisch und flexibel reagieren – es kann „spielen“. Dafür wurde es schließlich konzipiert. Sie haben eine moderne Multikern-Serverplattform randvoll mit High-Speed-RAM und Dutzenden paralleler CPUs.
Cachen Sie heiße Daten im RAM. Schützen Sie die RAM-Caches durch synchrones Spiegeln vor Einzelausfällen. Verarbeiten Sie I/O-Anfragen parallel auf so vielen CPUs wie möglich. Setzen Sie alle Ihre Zugpferde ein! Nutzen Sie jeden einzelnen Transistor in Ihrer Virtualisierungsimplementierung. Die durchschnittliche Latenz sinkt und der aggregierte Durchsatz steigt beträchtlich. Auch wenn man es nicht vermuten sollte: Virtualisierung erhöht tatsächlich die Performance.
Diese Vorteile werden durch das „Spielen“ mit dem Blockadressraum erreicht. Die komplexeren Speicherdienste wie die Erstellung von Snapshot–Kopien virtueller Disks oder die Verschlüsselung von Data-at-rest haben wir noch gar nicht angesprochen. Die Möglichkeiten sind praktisch grenzenlos.
I/O-Virtualisierung
Es gibt noch einen weiteren interessanten Aspekt der Blockspeichervirtualisierung. Vorhin haben wir über die Virtualisierung der Blockadressen gesprochen. Das ist nicht die einzige Möglichkeit. Wir können auch individuelle I/O-Anfragen virtualisieren.
Was bedeutet das? Hier geht es nicht so sehr um die Neuanordnung von Blöcken, sondern um die Art und Weise der Bearbeitung von Lese- und Schreibanfragen. Das eröffnet andere Möglichkeiten.
Anstatt Seiten mit Blockadressen wie ein virtuelles Memory-System neu anzuordnen, können wir die Daten in unserer Implementierung beliebig auslegen.
Wir können Sie sequenziell auslegen, wie ein Log. Das allein wirkt sich bereits positiv auf die Performance von Random-Write-Workloads aus.
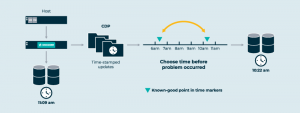
Wir können die Sequenz und Struktur individueller I/O-Anfragen in diesem Log ignorieren und uns darauf konzentrieren, wie sich das sequenzielle Layout auf den Durchsatz auswirkt. Doch wenn wir die Sequenz und die Struktur der individuellen Anfragen beibehalten, bauen wir ein Zeitelement in das Log ein. Auf einmal haben wir ein System, das Continuous Data Protection (CDP) unterstützt, in dem wir sofort ein Bild einer virtuellen Disk in einem früheren Zustand herstellen können. Von allen tollen Dingen, die man mit Software anstellen kann, zählen Zeitreisen vermutlich zu den Besten.
Dateivirtualisierung
Was wäre, wenn wir mit anderen Zugriffsmethoden spielen würden, um andere Speicherdomänen zu virtualisieren? Netzwerk-Dateisystemprotokolle bieten einen weiteren breiten Anwendungsbereich für die Virtualisierung. Auch hier umfasst die Zugriffsmethode eine API, die uns den Rahmen für eine Dateivirtualisierung bietet.
Dateispeichersysteme beinhalten Dateidaten und Dateimetadaten: die Namensraumhierarchie, Ordnernamen, Dateinamen, Dateierstellungs-, -zugriffs- und -änderungszeiten. Alles Dinge, mit denen das System spielen kann! Beginnen wir mit den Daten und Metadaten.
Trennung der Zuständigkeiten
Wir können Dateimetadaten von den Dateidaten trennen. Was bringt uns das? Bessere Organisation und Performance.
Stellen wir uns eine öffentliche Bibliothek aus einer Zeit vor, als es noch physische Kartenkatalogindizes gab. Es gibt einerseits den Kartenkatalogindex (die Metadaten) und andererseits die Bücher in den Regalen (die Daten).
Der Kartenkatalogindex ist für den schnellen, problemlosen Zugriff organisiert. Er befindet sich vorne in der Bibliothek und ist einfach erreichbar. Er ist nach Thema, Autor und Titel organisiert. Verglichen mit dem Bücherstapel ist der Index ziemlich klein. Der Index ist gemäß den Anforderungen der Nutzer organisiert und optimiert.

Die Bücher sind gemäß ihren unterschiedlichen Anforderungen an die Lagerung separat untergebracht. Seltene Bücher müssen in klimatisch kontrollierten, teuren Lagerbereichen mit wenig Verkehr gelagert werden. Taschenbücher befinden sich an einem anderen Ort – preiswerter, mit mehr Verkehr und in der Nähe der Fachliteratur. Größere Folianten und Quartbände wandern größenbedingt in spezielle Regale. Bücher, die nur selten jemand ausleiht, können extern untergebracht werden.

Das ist so normal und offensichtlich, dass wir keinen Gedanken daran verschwenden. Doch stellen Sie sich vor, der Kartenkatalog würde sich wie ein Faden quer durch die Bücherstapel und die Regale spannen. Dann erkennen Sie, welche Probleme eine Mischung von Metadaten und Daten für Anwendungen bereiten kann, die auf die Speichersysteme zugreifen.
Stellen Sie sich jetzt eine Bibliothek mit mehreren Zweigstellen vor. Die Zweigstelle könnte den gesamten globalen Buchbestand anbieten, auch wenn sich nur wenige Bücher tatsächlich vor Ort befinden. Wir teilen den Haupt-Kartenkatalog mit der Zweigstele, sodass die Nutzer dieses Katalogs den gesamten globalen Bestand sehen können (den Namensraum). Ein Liefersystem liefert die Bücher auf Anfrage. Das zeigt, wie sinnvoll die Trennung der Metadaten von den Daten ist. (Es zeigt auch, dass Informatiker eine Menge von Bibliothekaren lernen können, doch das ist eine andere Geschichte.)
Indem wir die Metadaten separat behandeln, können wir einen globalen Namensraum erstellen, der die Grenzen zwischen den Geräten auflöst. Wir können die Dateimetadaten gemäß den Anwendungs- oder Verwaltungsanforderungen ändern. Die Dateidaten können dabei nach einem anderen Plan mit ganz anderen Anforderungen bewegt werden. Wir können die Metadaten teilen, um die standortübergreifende Zusammenarbeit in einem universellen Namensraum zu ermöglichen. Wir können die Metadaten mit spezifischen Tags und Werten versehen und damit die Nützlichkeit (und den Wert!) der damit verbundenen Dateidaten erhöhen.
Die Trennung der Dateimetadaten von den Dateidaten nutzt auch der Performance. Die Parallel-NFS-Standards definieren den Vertrag zwischen Clients und Servern, sodass diese von den durch die Trennung der Zuständigkeiten entstehenden Leistungssteigerungen profitieren können.
Die Dateivirtualisierung verspricht, ebenso relevant und interessant zu werden, wie es die Blockspeichervirtualisierung seit 20 Jahren schon ist.
Was das für uns bedeutet
Mit der Zugriffsmethode erhalten Sie ein Virtualisierungsmodell, das Ihnen einen Ort liefert, an dem Sie Software und Rechenkapazität hinzufügen können – und damit die Grundlage und die Leistungsfähigkeit für fantasievolle Lösungen für Daten- und Speicherprobleme erhalten.
Virtualisierungssysteme kosten zwar etwas, doch sind sie ihren Preis meist mehr als wert. Wir können mit Sicherheit behaupten, dass sich Virtualisierung in vielen Fällen bezahlt macht. Wir können auch noch einen Schritt weitergehen und behaupten, dass Virtualisierung eigentlich immer vorteilhaft ist.
Und ganz ehrlich: Wir können sogar behaupten, dass die Vorteile der Virtualisierung nicht von der Hand zu weisen sind und für sich selbst sprechen. Um auf unser Sprichwort zurückzukommen: Wenn Sie Hardware sehen, lohnt es sich, ein paar Eier aufzuschlagen. Das Omelett ist Ihnen sicher.
