Kubernetes changed how infrastructure is consumed. Developers no longer need to file a ticket every time they need compute. They define an application, request resources, and let the platform schedule, scale, restart, and expose the workload. That model has transformed application delivery. But for many teams, persistent storage still feels stuck in the old world.
The developer asks for a PersistentVolumeClaim, but behind that simple request sits a chain of infrastructure decisions: storage classes, CSI drivers, performance tiers, access modes, snapshots, replication, capacity planning, backup policies, and often a ticket to a storage team. The YAML may look cloud-native. The operating model often does not. That is the real issue. Kubernetes storage is not just an infrastructure problem. It is a developer experience problem.
Developers do not want to think about arrays, LUNs, zoning, disk groups, replication topology, or backend storage policies. They want reliable persistent volumes on demand. They want storage that works the same way the rest of the platform works: self-service, automated, observable, and governed. This is where platform engineering becomes central.
The goal is not to make every developer a storage expert. The goal is to build a platform where storage expertise is encoded into the system, so developers can safely consume persistent storage without waiting on manual provisioning or navigating infrastructure complexity.
The PVC is Only the Front Door
Kubernetes gives developers a clean abstraction for persistent storage: the PersistentVolumeClaim.
A developer can request storage with a simple manifest:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-data
spec:
accessModes:
- ReadWriteOnce
storageClassName: fast-replicated
resources:
requests:
storage: 500GiOn the surface, this is exactly what cloud-native storage should look like. The developer declares intent. The platform provisions the volume. But a PVC is only the front door. What happens behind it determines whether the experience is smooth or painful.
Does the storage class provide the right performance? Is the volume replicated? Can it be expanded? Is it backed up? What happens if the node fails? Can the SRE team see latency, capacity, and replication health? Is the storage class approved for production? Who owns troubleshooting when the database slows down?
If those answers live in tribal knowledge, Slack threads, or ticket queues, the PVC has not solved the problem. It has simply hidden it until production. A good platform does not only expose storage. It makes storage understandable, reliable, and safe to consume.

Storage Friction is Delivery Friction
Storage delays rarely appear in productivity dashboards, but developers feel them immediately.
A team wants to deploy a PostgreSQL instance for a new service, but the right storage class is unclear. A data team wants to test Kafka, but no one knows which volume type can sustain the write pattern. An SRE team wants to restore a namespace after an incident, but volume recovery is handled separately from application recovery. A developer requests more capacity, but expansion requires manual approval.
Each of these moments creates friction. And friction compounds.
The problem is not that storage teams are slow or that developers are careless. The problem is that the workflow was not designed for cloud-native consumption. Traditional storage operations were built around infrastructure specialists. Kubernetes platforms are built around self-service.
When storage remains ticket-driven, platform velocity suffers.
Storage Classes are Platform Products
Platform engineering is about creating paved roads. It gives application teams a curated, supported path to production without forcing them to assemble every infrastructure component themselves. Storage should follow the same model.
Instead of exposing a long list of vague storage classes like gold, silver, premium, and standard, platform teams should define storage services around workload needs.
For example:
- dev-standard for non-production workloads
- database-ha for production databases requiring replication
- local-nvme for latency-sensitive workloads that manage their own replication
- analytics-throughput for high-throughput processing
- edge-replicated for distributed locations with limited infrastructure support
These are not just names. They are contracts. Each storage class should answer practical questions:
What is it for? Is it replicated? Is it backed up? Can it be expanded? What performance profile should teams expect? Is it approved for production? What failure behavior does it provide?
This is the difference between exposing infrastructure and offering a platform capability.
A developer should not need to ask, “Which array should I use?” The better question is, “Which storage service matches my workload?”
Self-service Does Not Mean No Governance
One concern with developer self-service is that it can become chaos. If every team can choose any storage class, ignore backup policy, and deploy stateful workloads without guardrails, the platform becomes risky. But the answer is not to return to tickets. The answer is automated governance.
Kubernetes provides the mechanisms: RBAC, admission control, namespace policies, resource quotas, labels, annotations, and GitOps workflows. Platform teams can define which storage classes are allowed in production, which require backup labels, which support expansion, and which are restricted to specific namespaces.
The best developer experience is not unlimited freedom. It is freedom within safe boundaries.
Developers should be able to move quickly without accidentally bypassing resilience, security, or compliance requirements. Storage policy should be built into the platform, not enforced manually after the fact.
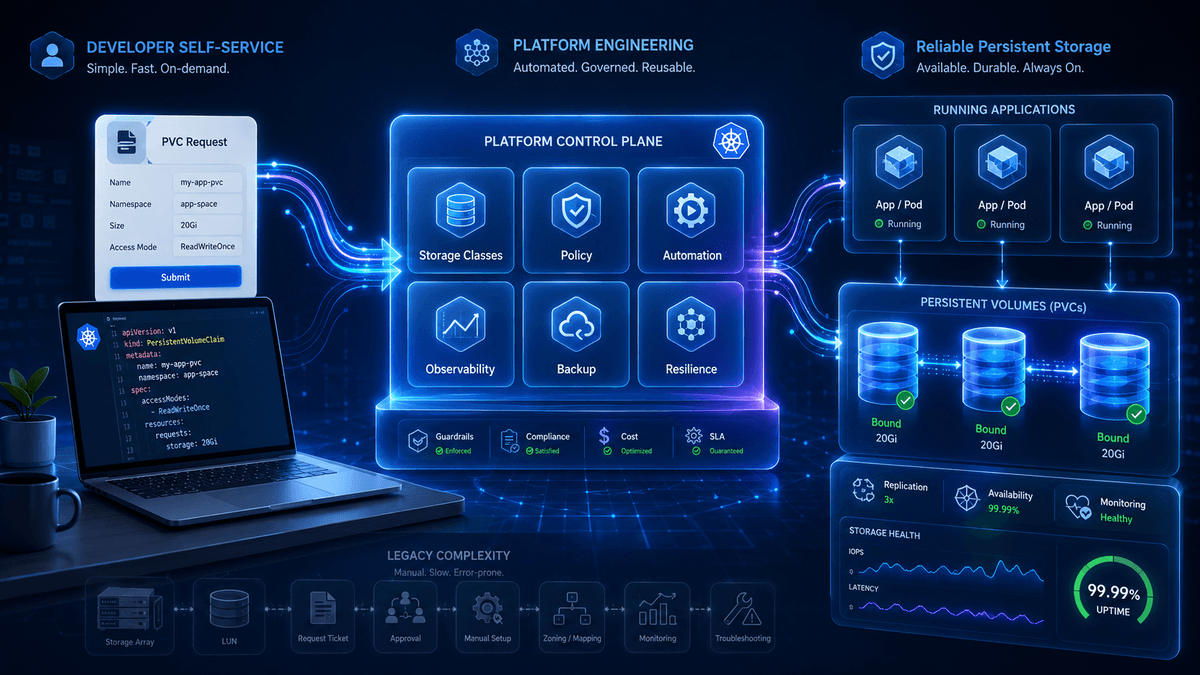
Observability Makes Storage Trustworthy
For stateful applications, storage issues often show up as application issues. A database slows down. A pod restarts. A queue backs up. A service misses its latency target.
The developer sees application symptoms. The platform team sees Kubernetes events. The storage team sees backend metrics. If these views are disconnected,
troubleshooting becomes a war room. That is why storage observability must move closer to the Kubernetes control plane.
Teams need to correlate application behavior with volume latency, node health, capacity pressure, replication status, and storage events. They need to answer questions like:
- Which PVCs are nearing capacity?
- Which workloads are using non-replicated volumes?
- Which volumes are attached to unhealthy nodes?
- Which stateful workloads are experiencing elevated latency?
- Which namespaces are consuming the most persistent storage?a
This matters for developers because visibility builds trust. It matters for platform teams because they cannot operate what they cannot see. And it matters for the business because stateful applications are increasingly mission-critical.
Why Container-Native Storage Matters
Traditional enterprise storage can provide powerful capabilities, but it was not always designed around Kubernetes as the primary operating model. Kubernetes-native storage changes the relationship between applications and persistence.
Container-native storage runs with Kubernetes, integrates with Kubernetes APIs, and exposes storage through Kubernetes-native constructs such as PVCs, storage classes, nodes, labels, and operators. It helps make storage part of the platform instead of an external dependency.
This is especially important as teams use local NVMe and SSD resources inside Kubernetes clusters. Local storage can deliver excellent performance, but raw local disks are not enough for production. They need provisioning, placement awareness, replication, failure handling, snapshots, backup integration, and observability.
Without a container-native storage layer, local disks can become fragile islands of capacity tied to individual nodes. Developers may get performance, but platform teams inherit operational complexity.
The better model is to make local and replicated storage available through the same Kubernetes-native experience developers already use. The developer asks for storage through a PVC. The platform delivers the right behavior behind the scenes. That is the critical shift: storage should not merely be attached to Kubernetes. It should behave like part of the Kubernetes platform.
Where DataCore Puls8 Fits
DataCore Puls8 is a container-native persistent storage platform designed for Kubernetes environments. It helps platform teams turn local node storage into persistent volumes with automation, resilience, and observability. Instead of forcing developers to understand the storage backend, Puls8 enables storage to be consumed through Kubernetes-native constructs such as PVCs and storage classes.
That matters because different workloads need different storage behaviors.
- Some workloads need low-latency access to local storage. Others need replicated persistent volumes for higher availability.
- Some are suited for development and test environments. Others support production databases, analytics platforms, or stateful services where resilience and visibility are essential.
Puls8 gives platform teams a way to expose those options as developer-friendly storage services rather than infrastructure tickets. Developers continue working through Kubernetes. Platform teams define the policies, storage classes, and operational expectations behind the scenes. Storage teams can apply their expertise through reusable platform patterns instead of one-off provisioning.
The result is a better operating model for stateful Kubernetes: faster consumption for developers, more consistency for platform teams, and less manual friction between application and infrastructure teams.
Storage is Now Part of the Developer Platform
Kubernetes has raised expectations. Developers expect infrastructure to be programmable. They expect self-service. They expect consistent environments. They expect observability. They expect the platform to help them move faster without making production fragile. Persistent storage has to meet those expectations.
The organizations that succeed with stateful Kubernetes will not be the ones that merely attach storage to clusters. They will be the ones that turn storage into a platform service: automated, governed, observable, resilient, and easy for developers to consume. That is the shift from PVCs to platform engineering.
Storage is no longer just something underneath the application. It is part of the developer experience. And in modern Kubernetes environments, developer experience is infrastructure strategy.
Ready to make Kubernetes persistent storage simpler for your platform and developer teams? Try DataCore Puls8 with a 30-day free download.
