NVMe (Non-Volatile Memory Express) is one of the current technology industry darlings. At a high level, NVMe is a protocol for accessing high-speed storage that promises to provide many advantages over legacy protocols such as SAS and SATA. The reason is that NVMe creates parallel, low latency data paths to underlying media to provide substantially higher performance and lower latency. In today’s world driven by the need for always-on, real-time data, this becomes a particularly attractive value proposition.
These promises lead some to believe that NVMe is essentially a “catch all.” As a result, many people don’t readily understand its relationship between similar technologies, such as Parallel I/O. The truth is that NVMe is a great technology that revolutionizes how applications interface non-volatile memory locally. However, NVMe doesn’t address how hosts share storage. It doesn’t address use cases where storage capacity exceeds what can be stuffed into a host. NVMe is only one part of a bigger picture within which we continue to see the struggle between serial vs. parallel I/O. As a result, NVMe and Parallel I/O are not mutually exclusive; rather, they are complementary technologies. Let’s explore how they relate to each other.
NVMe is an interface between a host and storage. NVMe overcomes a choke point in the host by exploiting the parallel potential of solid-state media. Applications requesting data go through the OS, which then accesses the media through a controller interface. Before NVMe, the controller presented a narrow register or memory interface to the host machine. The host and media communicate with each other through this narrow interface. This host-to-hardware interface was often single-threaded, requiring the host to serialize the threads wanting to access the media through that interface.
As an analogy, think of this hardware interface as a pair of mail slots in a door. You write a letter, push it out one mail slot, someone reads it, and sends the response letter through the other mail slot. Now imagine there are dozens of people with you on your side of that door. You all want to communicate with the other side, but you contend for that pair of slots in the door. So, you all queue up in an orderly fashion, each waiting their turn for access to the mail slot.
Wouldn’t it be easier and faster if that door had dozens, hundreds…even thousands of mail slot pairs? There would be enough for each person to have their own interface through the door! No more waiting in lines, no more contention. That’s what NVMe does. It specifies a hardware interface that flash controllers present to the host—lots of queue pairs (QPs). Each QP represents a parallel pathway for data flow between host and flash media. The flash chips on the other side are potentially massively parallel, having no moving heads or platters, or anything similar to that. With independent QPs presented to the host, independent requests can proceed in parallel from the host through the flash and back. NVMe allows an application with multiple processes/thread to access the same storage device in parallel, with each thread, running on a distinct CPU/core, and is able to drive I/O down to the storage concurrently.
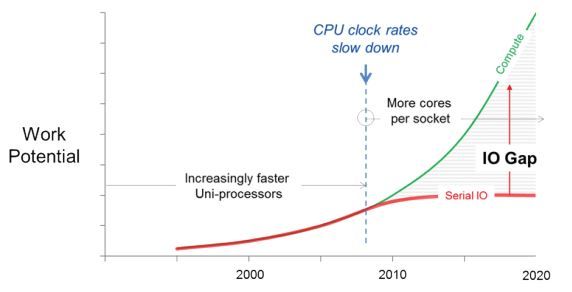
Now, let’s start with how NVMe escapes the physical boundaries of the host: NVMe over Fabric (NVMe-oF). This protocol promises to help deliver low latency and high parallelism over a fabric interconnect, so that compute and storage can scale independently. Those parallel lanes of data throughput within the host can now extend across a network. At the target end of that network, there needs to be a controller that can maintain the parallel processing of data access, from host CPU, through the fabric, through the controller to the flash media, and all the way back to the host.
That’s where Parallel I/O comes in. Parallel I/O is a subset of parallel computing that performs multiple I/O input/output operations simultaneously and helps eliminate I/O bottlenecks, which can stop or impair the flow of data. Rather than process I/O requests serially, one at a time, Parallel I/O accesses data on the disk simultaneously. This allows a system to achieve higher read and write speeds and maximizes bandwidth. Parallel I/O exploits multicore architectures to process I/O from applications in parallel and with maximum throughput and lowest latency.
Without Parallel I/O at the target end, you will have created a serialization point within the fabric itself, so CPUs in the initiating network of hosts all contend invisibly at the target controller, queueing up trying to access the flash media behind the fabric controller.
So, we see that as NVMe extends outside the host chassis into a fabric, and Parallel I/O is required to ensure the fabric does not itself become serialized.
To learn more about underlying parallel architecture, how it evolved over the years and how it results in a markedly different way to address the craving for IOPS (input/output operations per second) in a software-defined world, download the whitepaper, Waiting on IO: The Straw That Broke Virtualization’s Back!
