Metadata-driven data management of unstructured content will prove to be a disruptive storage technology in 2020.
Until recently, metadata has been limited to object storage systems, and has been tied to the data itself in most cases. But metadata can be extremely powerful, especially when it is tightly integrated with the data from a logic perspective, yet decoupled from a location perspective, while synchronized globally—and when it is available for all types of data, whether that data was stored using an object or a file protocol.
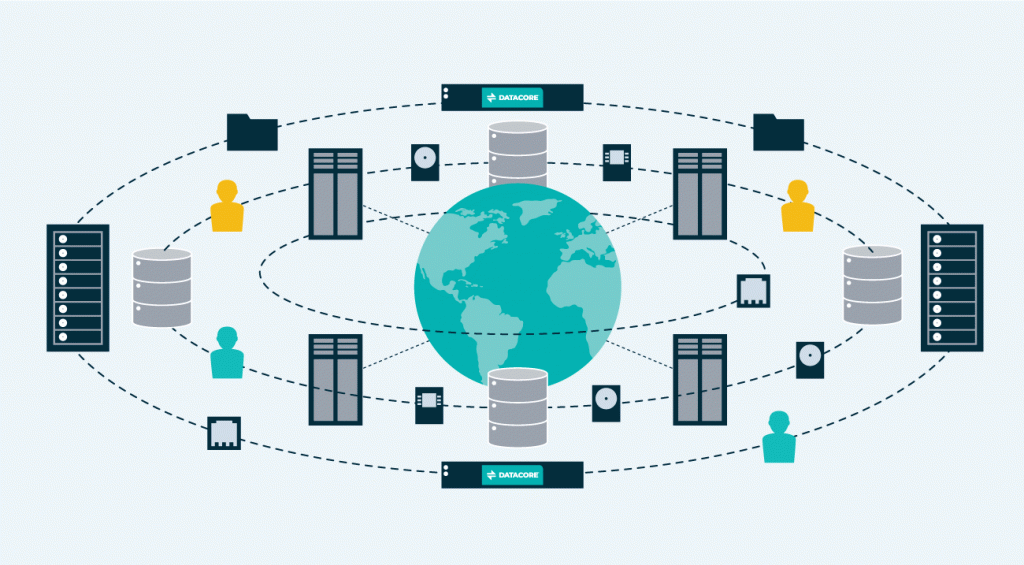
New metadata-driven capabilities allow organizations to build rich attributes around the data they store. For example, metadata can be used for data placement, compliance, to detect correlations and analyze relationships between seemingly unrelated documents and multimedia images, or to help catalog, organize, and search data—globally, across multiple storage systems and billions of files. Coupled with AI and machine learning (ML) technologies, telemetry and content scanning software, metadata can be enriched with searchable tags and other valuable attributes based on location, time, utilization, data characteristics and others.
