
Are you struggling with protecting and providing access to rapidly scaling data sets or enabling distributed content-based use cases? Using tape is cost-effective but data is not instantly accessible; and tape is difficult to manage. The public cloud often presents the challenge of compounding, unpredictable recurring costs, and the inability to meet local performance and privacy requirements.
DataCore Swarm provides an on-premises object storage solution that radically simplifies the ability to manage, store, and protect data while allowing S3/HTTP access to any application, device, or end-user. Swarm transforms your data archive into a flexible and immediately accessible content library that enables remote workflows, on-demand access, and massive storage scalability.
- Provides a scalable platform that can continually evolve by pooling any mix of x86 servers, HDDs and SSDs with 95% data storage capacity
- Automates storage and infrastructure management so a single system/IT administrator can manage dozens to hundreds of PBs
- Includes a web-based UI and API simplifying the management of hundreds of nodes, billions of files, thousands of tenants, and PBs of data
- A scale-out parallel architecture enables all nodes to perform all functions resulting in the ability to scale performance linearly
Use Cases
Here are some popular use cases of Swarm catering to different industry requirements. There are numerous other applications of Swarm in organizations and service provider environments.
Active Archive
Offloads data from primary NAS storage
Immutable Storage for Backups
Defends against data loss and threat vectors
Nearline Archive
Supports digital media workflows both in-facility and on-set (edge)
Origin Storage
For OTT/VOD services and content delivery
Medical Imaging Archive
Stores medical images, PACS, and VNA for healthcare sectors
Archive for Digital Asset Management
Protects assets, enabling low-latency access
Data Lake Storage
Handles massive workloads in research, big data, IoT, and AI/ML
Multi-tenant Storage
Facilitates various cloud service offerings (e.g., StaaS)
Long-term Data Preservation
Future-proofs content protection – no forklift upgrades
Alternative to Public Cloud and LTO Tape
Best-suited for online, on-premises data storage
*Energy and cost savings are estimates only; not a guarantee. Actuals may vary.
Want to learn more about Swarm and its Darkive functionality?
Features
- Unified web console for admins and end-users to track performance trends and mange/monitor content usage quotas
- Simplify capacity addition and hardware refresh with self-managing and self-healing architecture
- Stream content directly from the storage layer to internal employees or external subscribers
- Optimize data protection for performance or capacity through lifecycle policies
- Quickly search for data, customize metadata, and access files across a single namespace through S3 and HTTP(S)
- Easily manage thousands of tenants and billions of files across multiple sites and unlike devices
- Back up cold data from Swarm to Wasabi, S3 Glacier and object-based cloud and tape storage solutions
- Secure data through encryption, access controls, and integrity verification
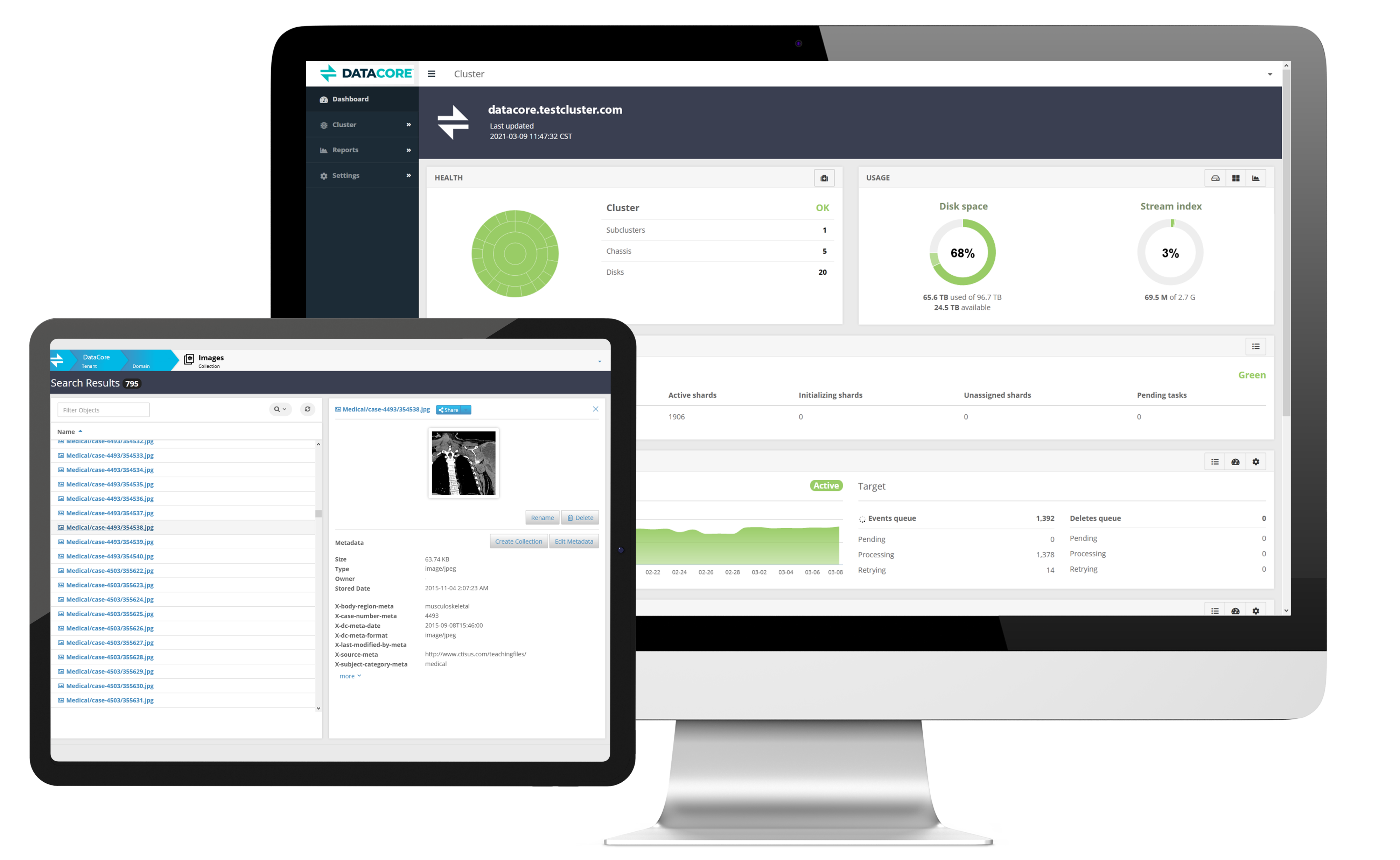
Manage storage, tenants, and data from any HTML5-enabled browser
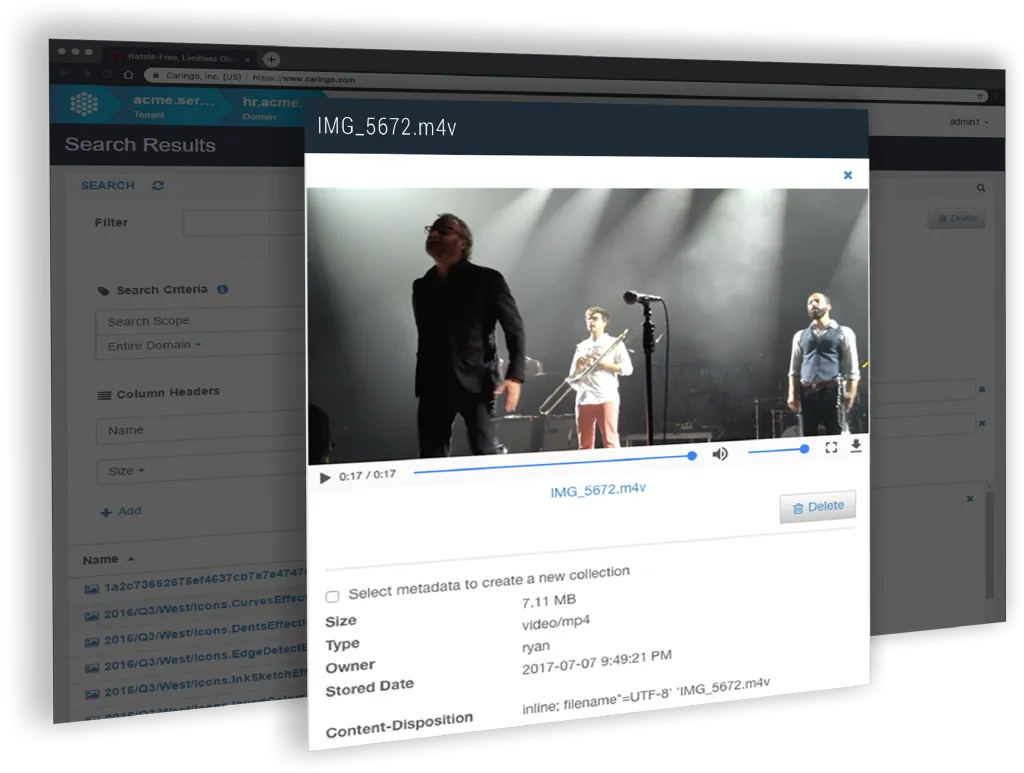
Securely share and stream content directly from Swarm object storage
The figure below highlights the various data and infrastructure management capabilities of DataCore Swarm including key data services, access methods and supported protocols. Explore features in detail.
Consumers
-
End-Users
-
Application & Web Services
-
Devices
Access Methods
-
S3
-
HTTP(S)
Operation & Insights
-
Identity &
Access Management -
End-User
Self-Service Portal -
Ad Hoc Search
& Query -
Monitoring &
Reporting -
Multi-Tenancy
Data Services
-
 WORM / Immutability
WORM / Immutability
-
 Synchronous Replication
Synchronous Replication
-
 Data Integrity Seals
Data Integrity Seals
-
 Asynchronous Replication & Disaster Recovery
Asynchronous Replication & Disaster Recovery
-
 Encryption
Encryption
-
 Erasure Coding
Erasure Coding
-
 Retention Scheduling
Retention Scheduling
-
 Self-Healing
Self-Healing
-
 Custom Metadata
Custom Metadata
-
 Dynamic Caching
Dynamic Caching
-
 Universal Namespace
Universal Namespace
-
 Cloud Integration
Cloud Integration
Command & Control
-
Web Console
-
REST API
-
Audit Logs,
Metering & Quotas -
S3 Object Lock
-
DARKIVE®
Energy Savings
Any Mix Of X86 Servers
-
HDD
-
SSD
Simplify and Streamline Data Management for Edge and ROBO
Single Node Swarm: Purpose-built for Small IT Environments
Benefits of Swarm Object Storage
Rapid Recovery
25X less down-time than traditional RAID storageSuperior Optimization
95% storage utilization for media and contentPerformance Ready
5X faster throughput for S3 read and write operationsSimplified Content Management

- Intuitive data classification, indexing, and dynamic search
- Policy-based replication for synchronous, asynchronous and stretch cluster uses
- Custom metadata for ad hoc search & query
- Share or stream files directly from the archive
Bulletproof Data Security

- Supports data encryption in transit and at rest
- Assure data immutability with Legal Hold, WORM integration, and S3 object locking
- Establish content integrity using Integrity Seals
- Track storage access and activity with audit trails
Multi-Tenant Administration

- Manage tenants, buckets, domains, and quotas
- Integrate with existing identity management systems such as LDAP, AD, ApacheDS, Linux PAM, token-based S3 and SSO/SAML 2.0 platforms
- Create detailed billing and accounting reports by domain based on bandwidth usage, access audits, etc.
Business Continuity and DR

- Maintain an always available active archive to retrieve data on-demand
- Increase data durability through erasure coding and replication at the cluster- or object-level
- Automatic failover and recovery
- Automated backup to Wasabi or Amazon Glacier for DR
Hassle-free Storage Scalability

- Start with just one server and easily add capacity and performance as required
- Expand to exabyte level storage with web-scale search and data access
- Add disks and server hardware of your choice to the Swarm cluster
- Extensible architecture supports Amazon S3 API and other third-party APIs
Cost Savings and Lower TCO

- High automation optimizes the utilization of resources, administrative time and budget
- No downtime hardware upgrades enable ability to continuously evolve underlying hardware
- Industry-leading 95% capacity for your data
- Energy savings through adaptive power conservation for disks
Object Storage Performance Benchmark: A Real-World Swarm Use Case with STFC
Flexible Deployment
Swarm runs on any standard x86 hardware and is highly available by design. Swarm software boots from RAM and utilizes only 5% of hard drive capacity for system data resulting in an industry-leading 95% capacity availability for your content. Scale up with disks and scale out with more nodes within a Swarm cluster, or even expand with more Swarm clusters as needed. With flexible deployment, you can add tenants and sites at any time. Swarm supports hot plug drives, adding/ retiring disks/nodes and rolling upgrades of the full software stack—all with no service downtime.

Bare Metal Deployment
Boot from bare metal on any x86 server using any mix of HDDs and SSDs.

Virtual Machine Deployment
Deploy Swarm on virtual machines (VMs) powered by VMware ESXi.

Containerized Deployment
Single-server installation with all Swarm services containerized and running on Kubernetes K3s.
Packaged Hardware Appliances are also available from our partners. Contact DataCore for more information
Use DataCore FileFly to Easily Offload Files from SMB Shares on NAS Devices and Windows Filers to Swarm
Licensing
Simple, transparent, and flexible licensing based on useable storage capacity in TB or PB across all of your Swarm instances.
Swarm object storage solution is typically used as an active archive, backup target, cloud storage, and content analytics and delivery platform. Licensing is the same regardless of what type of data is stored and managed and what use case Swarm is used for. Every Swarm term license includes Premier Support (24×7) and free product updates.
- Cost-effective term licensing (annual and multi-year licenses are available)
- Scale capacity as needed
- Price per TB goes down as consumption grows
- Volume discounts on total capacity in use apply
- Governmental and educational organizations are eligible for additional discounts
Additional Resources
Product Overview
White Papers & Case Studies
Get Started with Swarm, Software-Defined Object Storage
Store your growing data on scalable & secure active archive. No more insane cloud costs!
Join thousands of IT pros who have benefitted from DataCore solutions.

“Scalability is one of the slickest things about Swarm. One sweet thing with the platform is when you drop a new node in, it builds itself from the ground up. If you want to add a 72 TB or PB node you just drop it in.”
John Gillam – British Telecommunications
CTO for Cloud Services